Understanding Kubernetes Concepts – A QuickStart Guide
On July 21, 2015, when Kubernetes v1.0 was released, it redefined the container technology landscape. All the bottlenecks of application deployment, scaling, and management in containers was made simpler and faster with intelligent automation.
Container technology made software development more agile and brought in resource efficiency – they made scaling smoother and faster. However, they also need to be tracked, monitored, and managed, which is where container orchestration and Kubernetes come in.
Kubernetes is an open-source container-orchestration system for automating application deployment, scaling, and management. It was originally designed by Google and is now maintained by the Cloud Native Computing Foundation.
What does Kubernetes do?
Kubernetes allows you to leverage the full potential of your container ecosystem. With automation, it streamlines container workflow and frees up the IT team to concentrate on their core areas of application development by removing the need to manage container networking, storage, logs, alerting, etc. Overall, it automates deploying, scaling, and managing of containerized applications on a cluster of servers.
Key Benefits of Kubernetes
Flexibility for scaling – it enables horizontal infrastructure scaling by quickly adding or removing new severs. Kubernetes has the option of automating vertical scaling, too, by taking into account application provided metrics.
Health check and self-healing designed in Kubernetes allow it to maintain high availability of applications and infrastructure.
Enhanced deployment speed – with automated rollouts and rollbacks, canary deployments, and wide-ranging support for a variety of programming languages, Kubernetes speeds up the process of building, testing, and deploying new software.
Let’s understand more about Kubernetes concepts
1. Kubernetes Objects
Kubernetes contains several abstractions that represent the state of our system: deployed containerized applications and workloads, their associated network and disk resources, and other information about what our Kubernetes cluster is doing. These abstractions are represented by objects in the Kubernetes API. The basic Kubernetes objects include:
- Pod
- Service
- Volume
- Namespace
In this blog, we will look at the Pod and Service objects.
2. Pods
A pod is a higher level of abstraction grouping containerized components. A pod consists of one or more containers that are guaranteed to be co-located on the host machine and can share resources. The basic scheduling unit in Kubernetes is a pod. The host machines on which the pods are scheduled are called Nodes.
3. Pod definition yaml
Kubernetes objects are mostly created by declaring their configuration in a yaml file.
Given below is yaml file to define a simple pod.
apiVersion: v1 kind: Pod metadata: name: nginx labels: name: nginx spec: containers: - name: nginx image: nginx ports: - containerPort: 8080
In the above yaml file,
- apiVersion – denotes which version of the Kubernetes API we are using to create this object.
- kind – specifies what kind of object we want to create. For Pod object, the apviVersion is always v1.
- metadata – has data to uniquely identify the object (name) and labels.
- Labels are key/value pairs that are attached to objects. Labels are intended to be used to specify identifying attributes of objects that are meaningful and relevant to users but do not directly imply semantics to the core system. So, in the above example, instead of “name: nginx” we can have “appname: nginx”, “name: mynginxapp” or anything we like.
- Spec – defines the object specification and differs for each object type. For Pod object, the spec has an array of containers since a pod consists of one or more containers.
- For each container, we provide below attributes:
- name – name of the container. This can be different from name of pod and is not related to it.
- Image – name of the docker image to be used to build this container
- ports – the ports in this container to be exposed outside the pod. Here we are running the nginx web-server on port 8080 and exposing it.
Suppose we have the above pod definition in a file named pod-definition.yaml, the pod is created by executing the below Kubernetes command:
$ kubectl create -f pod-definition.yaml
4. Pod communication and need for services
Each pod in Kubernetes is assigned a unique Pod IP address within the cluster, which allows applications to use ports without the risk of conflict.
Within the pod, all containers can reference each other on localhost, but a container within one pod has no way of directly addressing another container within another pod; for that, it must use the Pod IP Address.
An application developer should never use the Pod IP Address though, to reference / invoke a capability in another pod, as Pod IP addresses are ephemeral – the specific pod that they are referencing may be assigned to another Pod IP address on restart. Instead, we should use a reference to a Service, which holds a reference to the target pod at the specific Pod IP Address.
5. Services
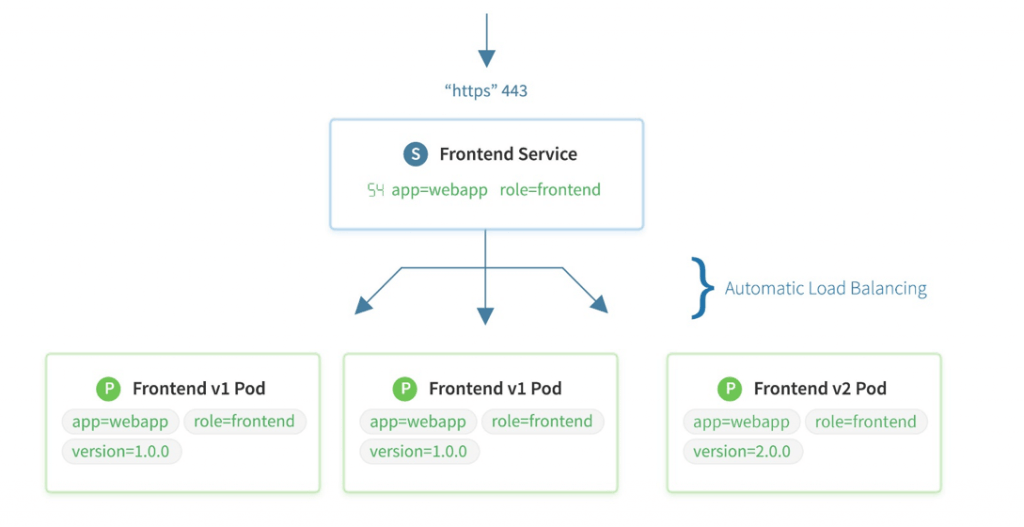
In Kubernetes, a Service is an abstraction that defines a logical set of Pods and a policy by which to access them. The set of Pods targeted by a Service is usually determined by a selector.
Sample YAML for a service to expose the pod(s) which we created earlier is given below:
apiVersion: v1 kind: Service metadata: name: my-service spec: selector: name: nginx ports: - protocol: TCP port: 80 targetPort: 8080 nodePort: 30230 type: NodePort
This yaml file defines a service named my-service which is used to access the Pods which have a label ‘name: nginx’.
- The selector field of the service must match the label field of the Pods to which we want to connect.
- There are 3 ports defined in above YAML file:
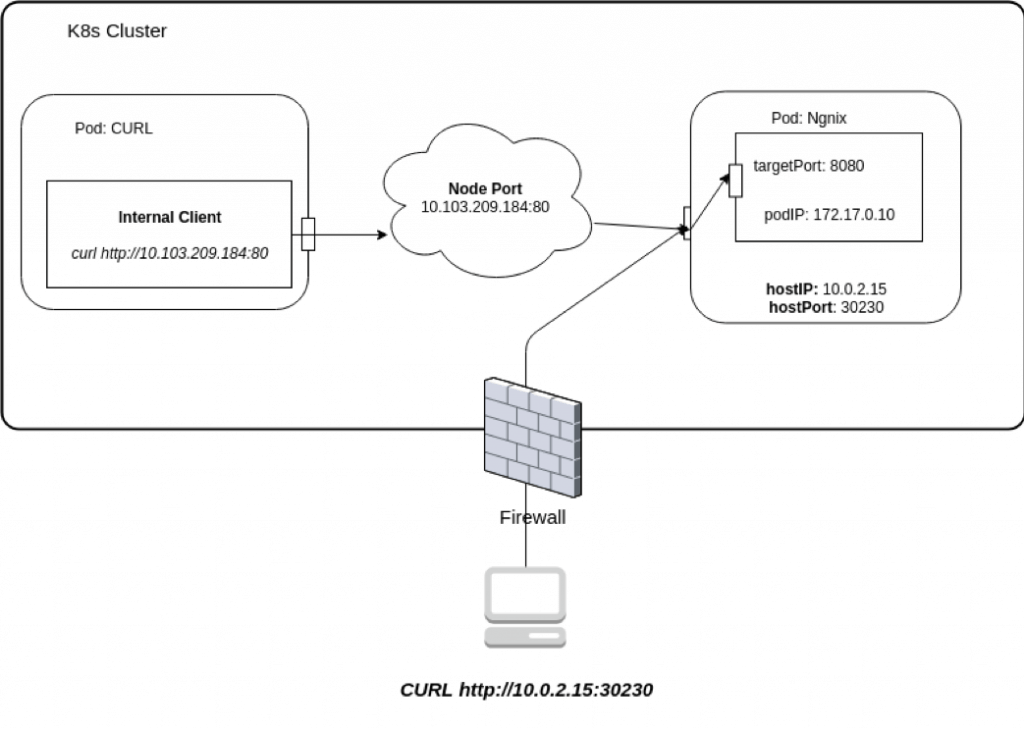
- Port is the port number that makes a service visible to other services running within the same Kubernetes cluster.
- Target Port is the port on the POD where the service is running. This is an optional field; if not provided, Kubernetes assigns the same value as Port field
- Node port is the port on which the service can be accessed by external users. NodePort can only have values from 30000 to 32767. If this optional field is not provided in the definition, Kubernetes automatically assigns a value for NodePort service.
To create the service object, enter the above yaml code in a file named service-defn.yaml and execute the command given below:
$ kubectl create -f service-defn.yaml
6. Types of Services
In the above example, we have type: Nodeport for the service. The different values allowed for the type field are:
- ClusterIP: Exposes the Service on a cluster-internal IP. Choosing this value makes the Service only reachable from within the cluster. This is the default Service type.
- NodePort: Exposes the Service on each Node’s IP at a static port (the NodePort). A ClusterIP Service, to which the NodePort Service routes, is automatically created. We will be able to contact the NodePort Service, from outside the cluster, by requesting <NodeIP>:<NodePort>
- LoadBalancer: Exposes the Service externally using a cloud provider’s load balancer. NodePort and ClusterIP Services, to which the external load balancer routes, are automatically created.
- ExternalName: Maps the Service to the contents of the externalName field (e.g., foo.bar.example.com), by returning a CNAME record with its value. No proxying of any kind is set up. We need CoreDNS version 1.7 or higher to use the ExternalName type.
Share this:
CloudIQ is a leading Cloud Consulting and Solutions firm that helps businesses solve today’s problems and plan the enterprise of tomorrow by integrating intelligent cloud solutions. We help you leverage the technologies that make your people more productive, your infrastructure more intelligent, and your business more profitable.
LATEST THINKING
INDIA
Chennai One IT SEZ,
Module No:5-C, Phase ll, 2nd Floor, North Block, Pallavaram-Thoraipakkam 200 ft road, Thoraipakkam, Chennai – 600097
© 2023 CloudIQ Technologies. All rights reserved.