Migrating from PostgreSQL to CosmosDB using Azure Data Factory
When systems evolve the need to migrate database does arise based on the data we are dealing with. In one of our projects, we had a scenario where non-transactional data had to be accessed frequently with low latency across regions. Azure Cosmos DB is Microsoft’s fast NoSQL database and the first globally distributed database service in the market today to offer comprehensive service level agreements encompassing throughput, latency, availability, and consistency.
So, the choice was clear for us to move the data from PostgreSQL to CosmosDB. In PostgreSQL the data format is flat (i.e., in the form of tables and columns), while CosmosDB supports flexible schemas and hierarchical data, and thus it is well suited for storing catalog data. Provides. JSON format supported by Cosmos DB is an effective format that is very lightweight.
For the data migration from PostgreSQL to CosmosDB we chose Azure Data Factory. Azure Data Factory helps you integrate, perform transformations, and visualize all your data with ease. Azure Data Factory is easy to use, cost-effective, a fully serverless cloud service that accelerates data transformation with code-free data flows.
Data Transformation using Azure Data Factory
Azure Data Factory is an orchestration tool that is used to transform the data from one source to another. It can process and transform the raw data into predictions and insights. It allows you to perform data transformation activities via pipelines. Data flows are created in debug mode to validate the logic of the transformation. The data flow activity is added to the pipeline to execute and test the data flow. And “trigger now” is employed to test the data flow that is in the pipeline.
Several options are available for converting JSON data to flat data, however when it comes to converting flat data into JSON, it is still a challenge. With JSON, inserting null value within the data flow is quite tedious and a unique pipeline must be created to handle null values.
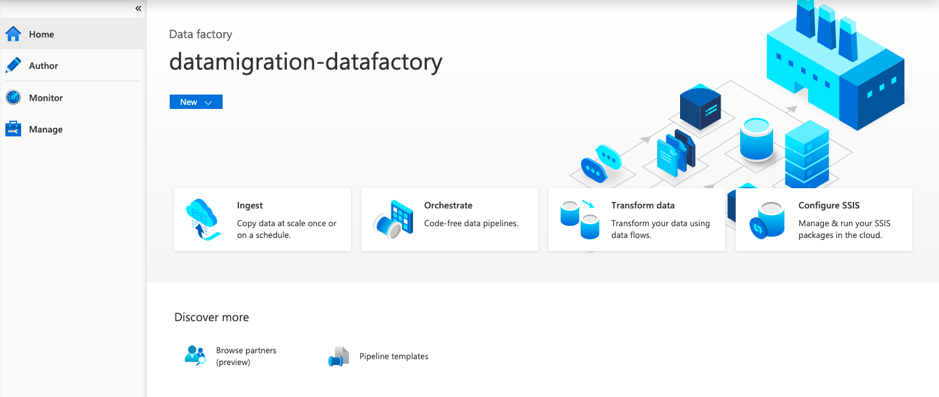
The Azure Data factory has three main options:
- Author
- Monitor
- Manage
The Author option provides the main environment for development. Using this option, we can design and manage Azure Data Factory resources such as the pipelines and dataflows.
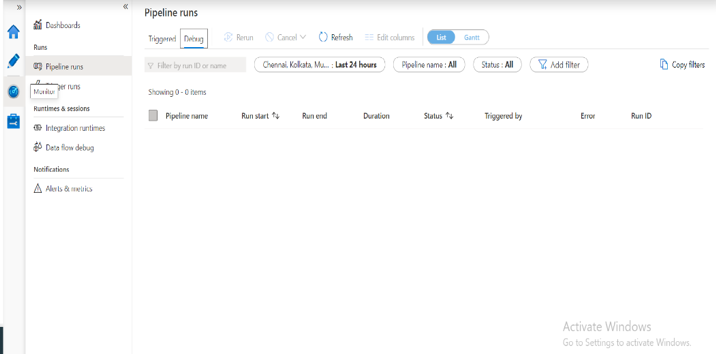
The Monitor option allows you to monitor the pipelines; trigger runs; sessions; the time taken for execution and running the pipelines; check if the execution of the pipeline was a success or failure and set up alerts.
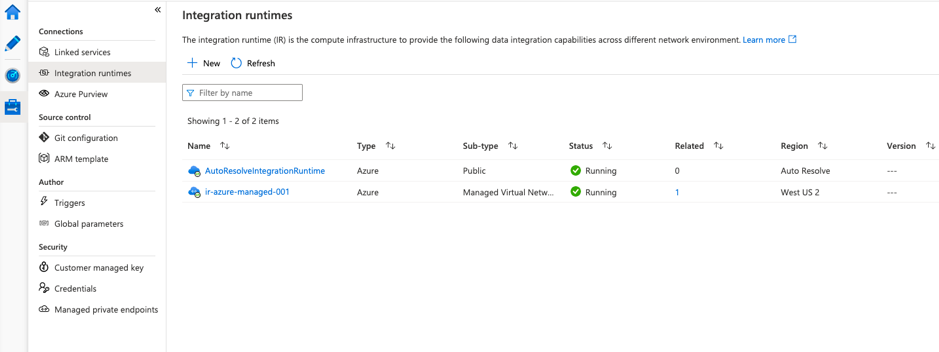
The Manage option allows you to manage the connections, link service, source control, triggers, parameters, and security.
Now let’s look at how to migrate from PostgreSQL to CosmosDB and transform the data.
Pipeline and activities creation
The Author option provides the environment for the development of pipelines and data flows. So, the first step is to create a pipeline that contains the data flow activity. The pipeline is a logical grouping of activities that perform a task. By clicking on orchestrate on the home page, we create and name the pipelines.
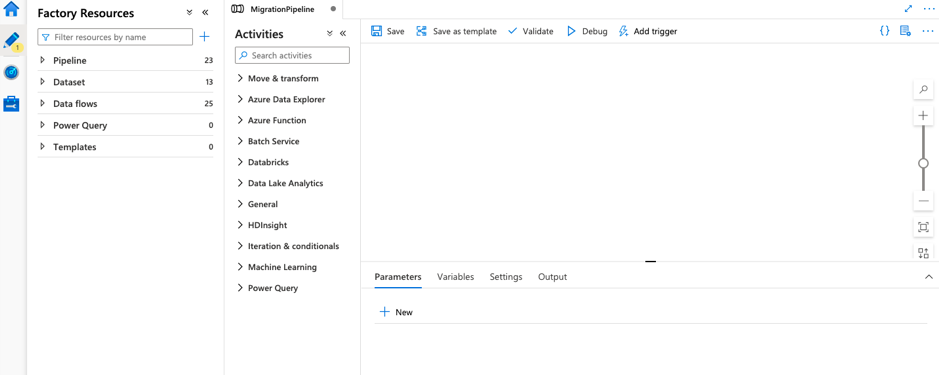
The activities pane allows you to perform various activities such as move, transform, add data flow (we can use existing data flows or even create new data flows), Azure data explorer, Azure function, Batch Service, Databricks, Data Lake Analytics, etc. Once the data flow is created, we can provide the transformation logic in the data flow canvas. The dataflows distribute the processing of data over different nodes in a Spark cluster to perform the operations parallelly. We need to create a mapping data flow to perform the transformation as well.
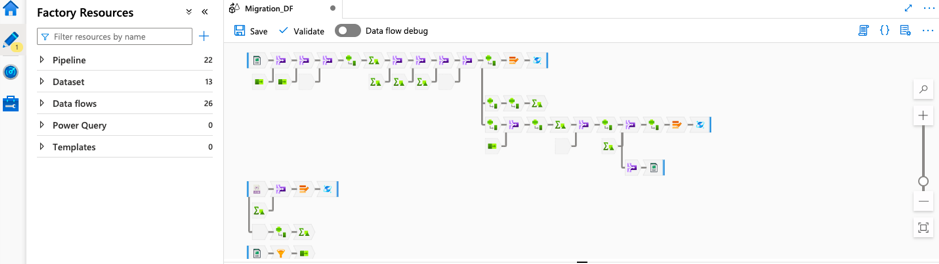
We can choose the format of the data as per the requirement. We can also select the dataset, which is simply the view of data or the references of the data that you want to employ in your activity.
In our data migration scenario, say for an activity to copy data from the source (PostgreSQL data directory), the data is taken from the source and put in the blob storage. The basic details are stored in the first copy activity, the patient color details are stored in the second, microchip details are stored in the third, breed details in the fourth and existing patient details are stored in the fifth copy activity respectively. The data flow performs transformations to the data such as join, conditional join, aggregate, pivot, flatten, union, split, etc. And finally, triggers are scheduled for doing transformation in the pipelines.
Linked Service and Integration Runtime
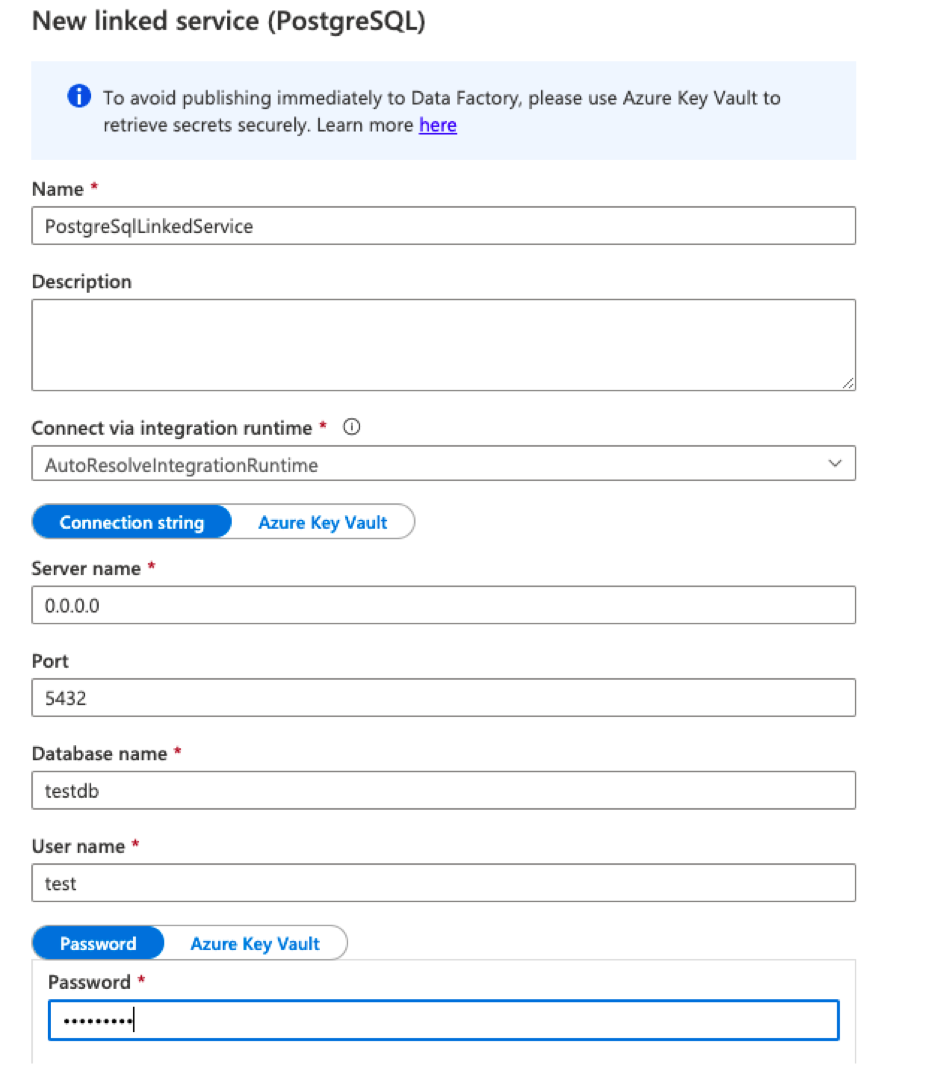
When creating a dataset, first we must create a linked service to link the data store to Data Factory via the management hub. Linked services are much like connection strings and defines the connection to the data source.
In our data migration scenario, we have created the following linked services for Azure Managed Instance, Azure Blob storage, CosmosDB (one for dev and one for UI), and PostgreSQL. To create the linked service, we must provide the server’s name, port, database name, username, password, etc. These are the input for dataflow to connect to the specific database. In this migration, the PostgreSQL data is migrated from a different VM environment into the Azure environment.
Here, the base directory is called containers, inside the containers we have several directories which further contain storage files.
The integration runtime via the management hub is the compute infrastructure for providing data integration capabilities such as data flow, data movement, activity dispatch, and SSIS package execution across different network environments. It provides the linkage between the activity and linked services. The default option is public for the Auto-resolve integration runtime. We can also create private customized ones based on the requirement for dataflow execution.
We hope this walkthrough of migrating data from PostgreSQL to Azure CosmosDB using Azure Data Factory was helpful. If you have queries or want us to help you with your data migration projects, feel free to reach out to us.
Share this:
CloudIQ is a leading Cloud Consulting and Solutions firm that helps businesses solve today’s problems and plan the enterprise of tomorrow by integrating intelligent cloud solutions. We help you leverage the technologies that make your people more productive, your infrastructure more intelligent, and your business more profitable.
LATEST THINKING
INDIA
Chennai One IT SEZ,
Module No:5-C, Phase ll, 2nd Floor, North Block, Pallavaram-Thoraipakkam 200 ft road, Thoraipakkam, Chennai – 600097
© 2023 CloudIQ Technologies. All rights reserved.