How to Create and Run Spark Clusters with Qubole using AWS
There is little doubt that data will guide the next generation of business strategy and will bring new efficiencies across industries. But for that to happen, organizations must be able to extract insights from their data.
Qubole is an ideal platform to activate end-to-end data processing in organizations. It combines all types of data – structured, unstructured, and legacy offline data – into a single data pipeline and turns it into rich insights by adding AI, ML, and deep analytics tools to the mix.
It scales seamlessly to accommodate more users and new data without adding administrative overheads and lowers cloud costs significantly. Simply put, Qubole is a platform that puts big data on the cloud to power business decisions based on real-time analytics.
At CloudIQ Technologies, our data experts have deployed Qubole’s cloud-native data systems for many of our clients, and the results have been outstanding. Here is an article from one of our data engineers that provides an overview of how to setup Qubole to use AWS environment and create and run spark clusters.
AWS Access Configuration:
In order for Qubole to create and run a cluster, we have to grant Qubole access to our AWS environment. We can grant access based on a key or a role. We will use role-based authentication.
Step 1: Login to Qubole
Step 2: Click on the menu at the top left corner and select “Account Settings” under the Control Panel.
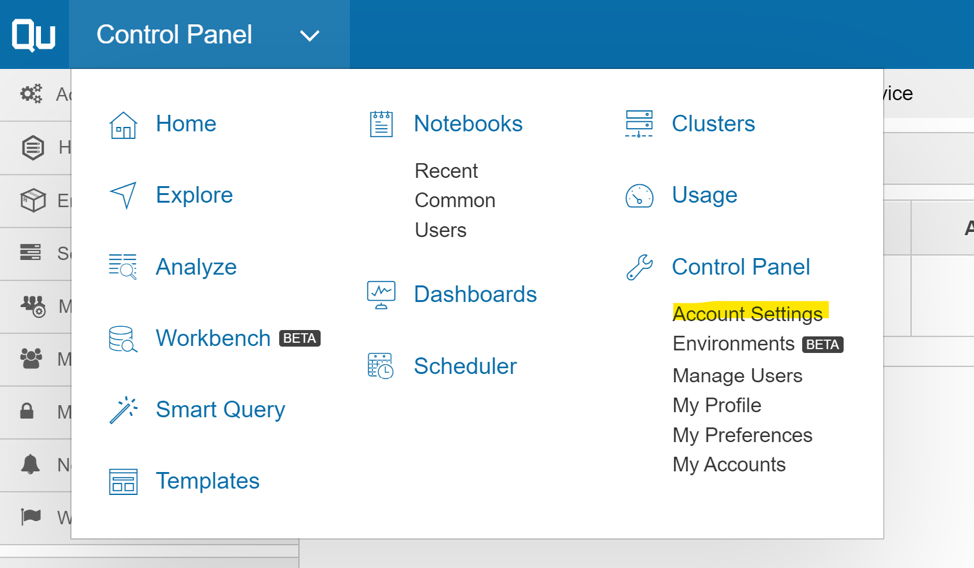
Step 3: Scroll down to Access settings
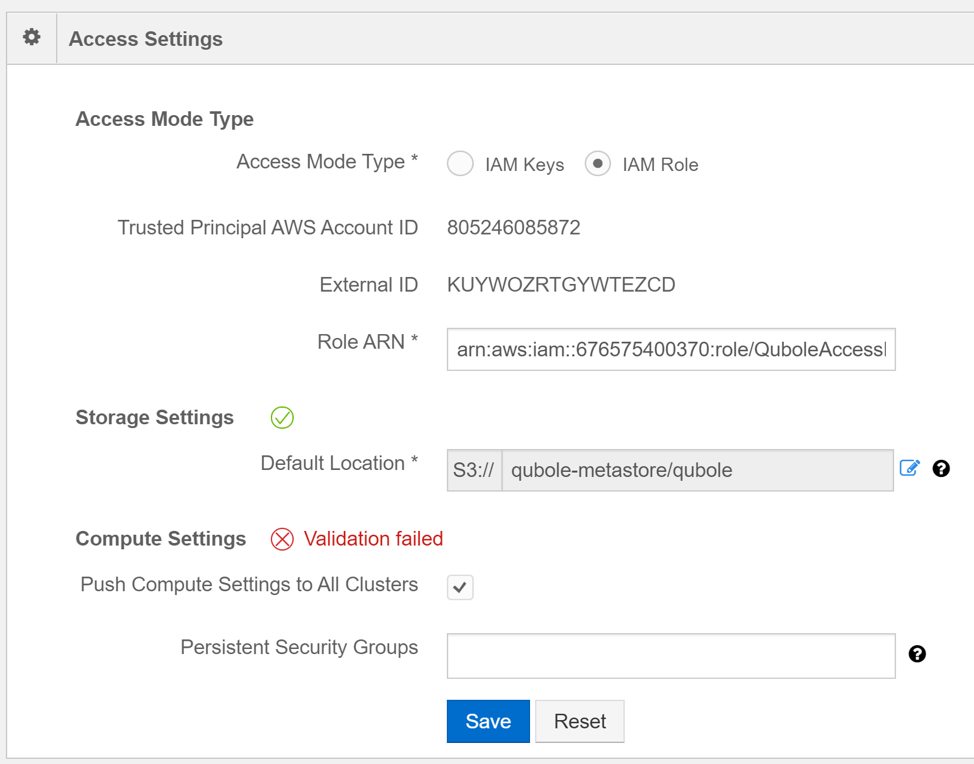
Step 4: Switch Access mode to “IAM Role”
Step 5: Copy the Trusted Principal AWS Account ID and External ID
Step 6: Use the copied values to create a QuboleAccessRole in the AWS account (using the cloudformation template)
Step 7: Copy the Role ARN of the QuboleAccessRole and enter it in the Role ARN field
Step 8: Enter the S3 bucket location where the Qubole metadata will be stored in the “Default Location” field.
Step 9: Click Save
Spark Cluster
Create a cluster
The below steps will help create a new Spark cluster in Qubole.
Step 1: Click on the top-left dropdown menu and select “Cluster”
Step 2: Click on “+New” button
Step 3: Select “Spark” and click “Next”
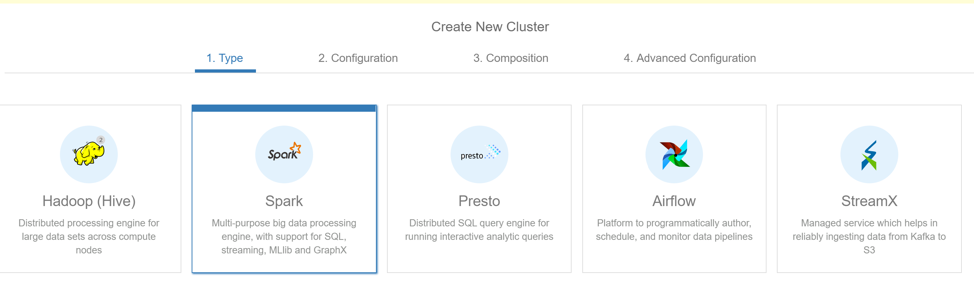
Step 4: Provide a name for the cluster in the “Cluster Labels” field
Step 5: Select the version of Spark to run, Master Node Type, Worker Node Type, Minimum and Maximum nodes
Step 6: Select Region as us-west-2
Step 7: Select Availability Zone as us-west-2a
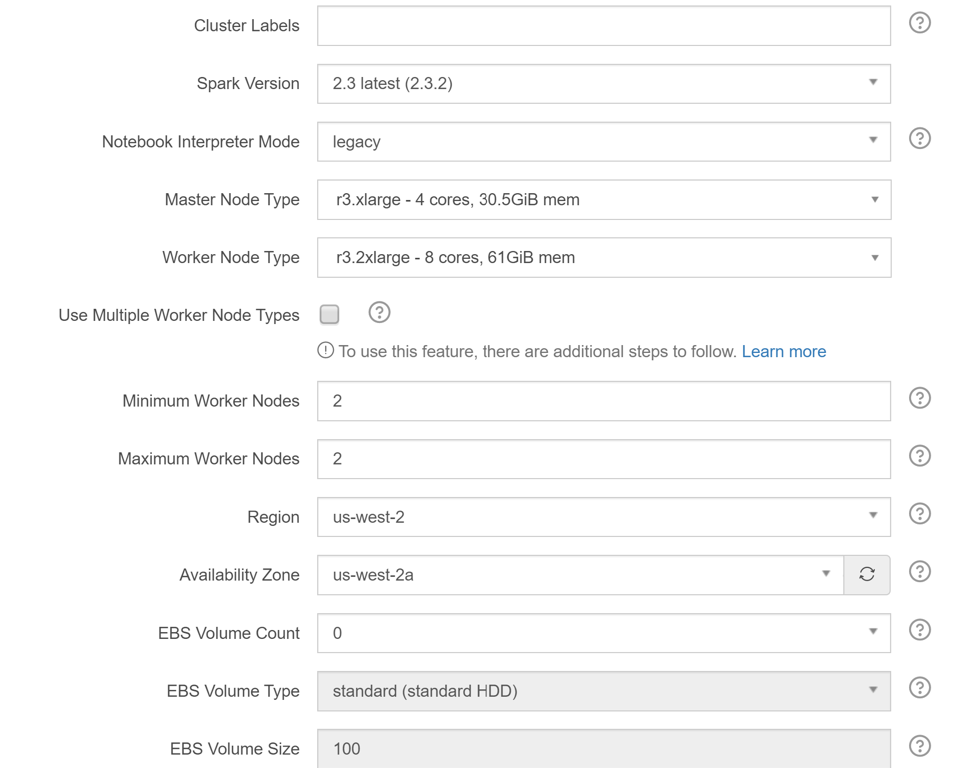
Step 8: Click “Next”
Step 9: In the Composition screen, you can select the type of nodes that will be spun up.
Step 10: In the Advanced Configuration screen, proceed to EC2 settings
Step 11: Enter “QuboleDualIAMRole” in the “Instance Profile” field
Step 12: Select “AppVPC” in VPC field
Step 13: Select “AppPrivateSNA” under Subnet field
Step 14: Enter the ip address of the Bastion node in the “Bastion Node” field
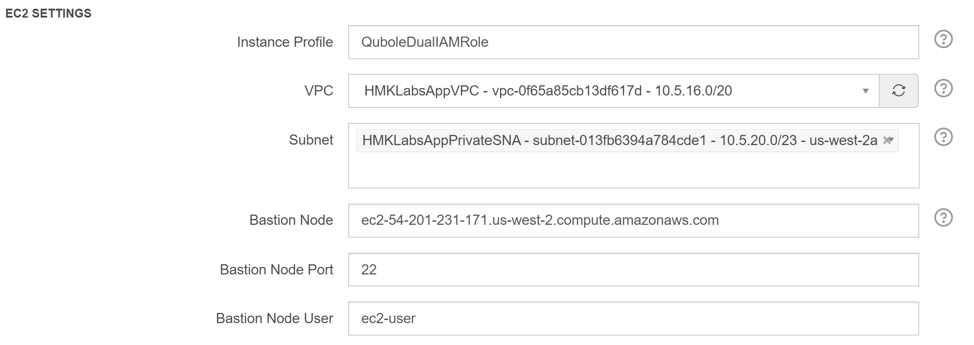
Step 15: Scroll to the bottom and enter “AppQuboleClusterSG” (security group for the cluster) in the “Persistent Security Group” field
Step 16: Click on “Create”
Run a cluster
To start a cluster, click on the dropdown menu on the top left corner and select cluster. Now click on “Start” button next to the cluster that needs to be started. A cluster is also automatically started when a job is submitted for the cluster.

Submit a job
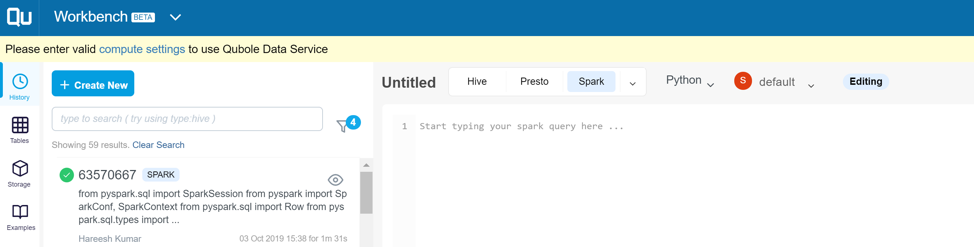
One of the simplest ways to run a spark job is to submit it through the workbench. You can navigate to the workbench from the drop-down menu at the top left corner. In the workbench, click on “+Create New”. Then select “Spark” next to the title of the job. Once you select Spark, an optional drop-down appears where you can choose “Python”. In the last drop-down menu, select the spark cluster where you want to execute the job. If this cluster is not active, it will be activated automatically. Enter your spark job in the window below. When complete, click on “Run” to run the job.
Airflow Cluster
Airflow scheduler can be used to run various jobs in a sequence. Let’s take a look at configuring an Airflow cluster in Qubole.
Setting up DataStore
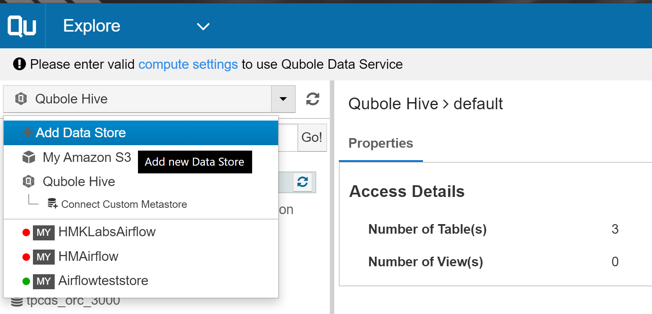
The first step in creating an airflow cluster is to set up a datastore. Make sure that the MySQL db is up and running and contains a database for airflow. Now, select “Explore” from the dropdown menu at the top left corner. On the left hand menu, drop down the selection menu showing “Qubole Hive” and select “+Add Data Store”
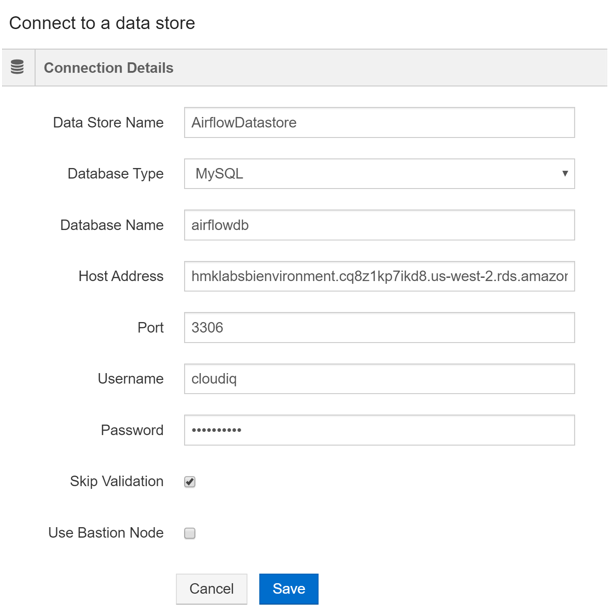
In the new screen, provide a name for the data store. Select “MySQL” as the database type. Enter the database name for the airflow database (The database should already be created in MySQL). Enter the host address as “hmklabsbienvironment.cq8z1kp7ikd8.us-west-2.rds.amazonaws.com”. Enter the username and password. Make sure to select “Skip Validation”. Since the MySQL db is in a private VPC, Qubole does not have access to it and will not be able to validate.
Configuring Airflow Cluster
Step 1: Click on the top left drop-down menu and select “Cluster”
Step 2: Click on “+New” button
Step 3: Select “Airflow” in the type of cluster and click “Next”
Step 4: Give a cluster name. Select the airflow version, node type.
Step 5: Select the datastore which points to the MySQL
Step 6: Select the us-west-2 as the Region
Step 7: Select us-west-2a as the Availability zone
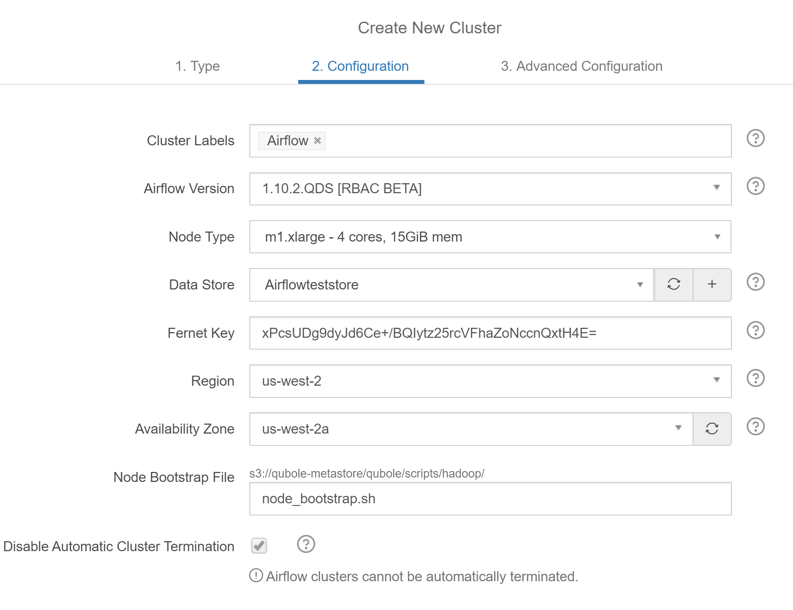
Step 8: Click next to go to Advanced Configuration
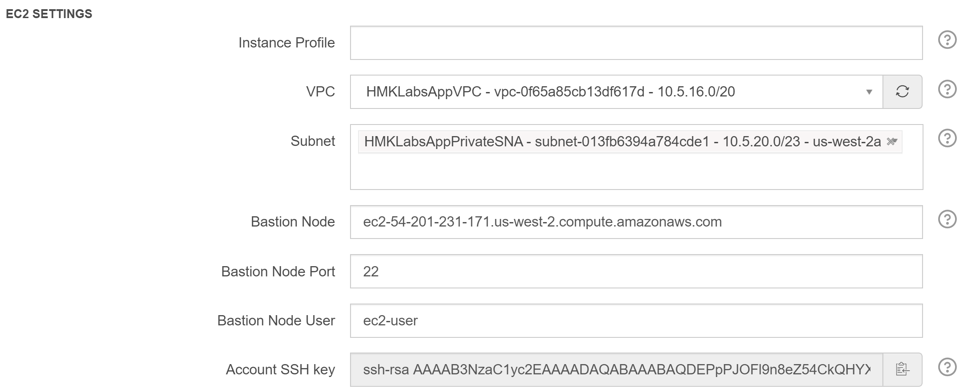
Step 9: Select AppVPC as the VPC
Step 10: Select AppPrivateSNA as the Subnet
Step 11: Enter the Bastion Node information
Step 12: Scroll to the bottom and enter AppQuboleClusterSG as the Persistent Security Groups
Step 13: Click on create

Once the cluster is created, you can run it by clicking on “Start” next to the cluster’s name.
Share this:
CloudIQ is a leading Cloud Consulting and Solutions firm that helps businesses solve today’s problems and plan the enterprise of tomorrow by integrating intelligent cloud solutions. We help you leverage the technologies that make your people more productive, your infrastructure more intelligent, and your business more profitable.
LATEST THINKING
INDIA
Chennai One IT SEZ,
Module No:5-C, Phase ll, 2nd Floor, North Block, Pallavaram-Thoraipakkam 200 ft road, Thoraipakkam, Chennai – 600097
© 2023 CloudIQ Technologies. All rights reserved.