How to build real-time streaming data pipelines and applications using Apache kafka?
Messaging system
A Messaging System is responsible for transferring data from one application to another, so the applications can focus on data, but not worry about how to share it. In Big Data, an enormous volume of data is used.
Two types of messaging patterns are available:
Messaging system
In a point-to-point system, messages are persisted in a queue. One or more consumers can consume the messages in the queue, but a particular message can be consumed by a maximum of one consumer only.

Publish-Subscribe Messaging System
In the publish-subscribe system, messages are persisted in a topic. Unlike point-to-point system, consumers can subscribe to one or more topic and consume all the messages in that topic. In the Publish-Subscribe system, message producers are called publishers and message consumers are called subscribers.
Kafka
Apache Kafka is a distributed publish-subscribe messaging system and a robust queue that can handle a high volume of data and enables us to pass messages from one end-point to another.
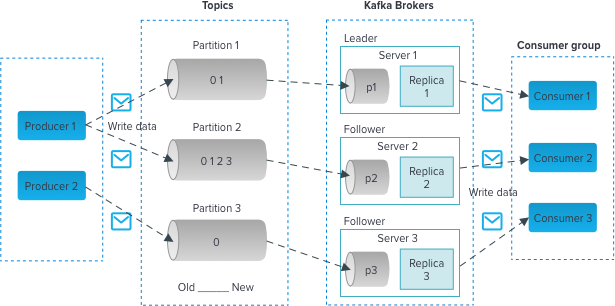
The following diagram illustrates the main terminologies.
Topics
A stream of messages belonging to a category is called a topic. Data is stored in topics. Kafka topics are analogous to radio / TV channels. Multiple consumers can subscribe to same topic and consume the messages.
Topics are split into partitions. For each topic, Kafka keeps a minimum of one partition. Each such partition contains messages in an immutable ordered sequence.
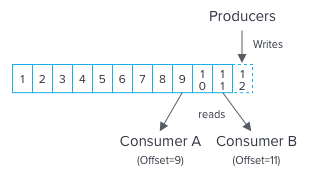
Partition offset
Each partitioned message has a unique sequence id called as offset. For each topic, the Kafka cluster maintains a partitioned log that looks like this:
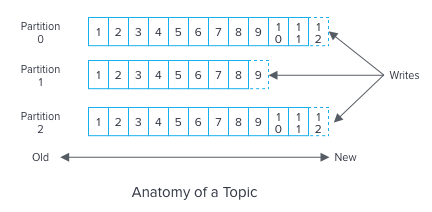
Each partition is an ordered, immutable sequence of records that is continually appended to—a structured commit log. The records in the partitions are each assigned a sequential id number called the offset that uniquely identifies each record within the partition.
The Kafka cluster durably persists all published records—whether or not they have been consumed—using a configurable retention period. For example, if the retention policy is set to two days, then for the two days after a record is published, it is available for consumption, after which it will be discarded to free up space.
Replicas of partition
Replicas are nothing but backups of a partition. Replicas are never read or write data. They are used to prevent data loss.
Brokers
Brokers are simple system responsible for maintaining the published data. Each broker may have zero or more partitions per topic.
Kafka Cluster
Kafka’s having more than one broker are called as Kafka cluster.
Kafka Cluster Architecture
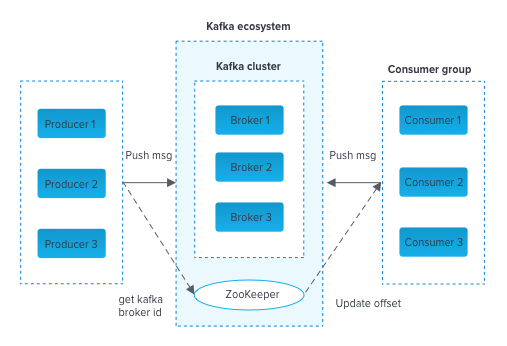
Zookeeper
ZooKeeper is used for managing and coordinating Kafka broker. ZooKeeper service is mainly used to notify producer and consumer about the presence of any new broker in the Kafka system or failure of the broker in the Kafka system.
Consumer Group
Consumers label themselves with a consumer group name, and each record published to a topic is delivered to one consumer instance within each subscribing consumer group.
Kafka features
- High Throughput: Provides support for hundreds of thousands of messages with modest hardware.
- Scalability: Highly scalable distributed system with no downtime
- Data Loss: Kafka ensures no data loss once configured properly
- Stream processing: Kafka can be used along with real time streaming applications like Spark and Storm
- Durability: Provides support to persisting messages on disk
- Replication: Messages can be replicated across clusters, which supports multiple subscribers
Installing and Getting started
Prerequisite: Install Java
- Download kafka .tgz file from https://kafka.apache.org/downloads
- Untar the file and go into the kafka directory
> tar -xzf kafka_2.11-2.1.0.tgz > cd kafka_2.11-2.1.0 - Start the zookeeper server using the properties in zookeeper.properties
> bin/zookeeper-server-start.sh config/zookeeper.properties - iv. Start the Kafka broker using the properties in server.properties
> bin/kafka-server-start.sh config/server.properties
Create a topic
Let’s create a topic named “test” with a single partition and only one replica:
In below command 2181 is the port number we have specified in zookeeper.properties
> bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic test
To list the current list of topics, we can query the zookeeper using below command:
> bin/kafka-topics.sh --list --zookeeper localhost:2181
Test
Command line producer
Kafka comes with a command line client that will take input from a file or from standard input and send it out as messages to the Kafka cluster. By default, each line will be sent as a separate message. Run the producer and then type a few messages into the console to send to the server
(In below command 9092 is the port number we configured for the broker in server.properties)
> bin/kafka-console-producer.sh --broker-list localhost:9092 --topic test
This is a message
This is another message
Command line consumer
Kafka also has a command line consumer that will dump out messages to standard output.
> bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test --from-beginning
This is a message
This is another message
Kafka producer and consumer using python
The Kafka producer and consumer can be coded in many languages like java, python, etc. In this section, we will see how to send and receive messages from a python topic using python.
- First we have to install the kafka-python package using python package manager.
pip install kafka-python - Below python program reads records from an input file and sends them as messages to the test topic which we created in previous section
Producer.py
from kafka import KafkaProducer producer = KafkaProducer(bootstrap_servers=['localhost:9092']) with open('/example/data/inputfile.txt') as f: lines = f.readlines() for line in lines: producer.send('test', line)
Below python program consumes the messages from the kafka topic and prints them on the screen.
Consumer.py
from kafka import KafkaConsumer
consumer = KafkaConsumer(bootstrap_servers=['localhost:9092'], auto_offset_reset='earliest')
consumer.subscribe(['test'])
for msg in consumer:
print(msg)
In the above program, we have
auto_offset_reset=’earliest’.
This will cause the consumer program to read all the messages from beginning if the same program is run again and again.
Instead if we have
auto_offset_reset=’latest’,
the consumer program will read messages starting from the latest offset which was consumed earlier.
Share this:
CloudIQ is a leading Cloud Consulting and Solutions firm that helps businesses solve today’s problems and plan the enterprise of tomorrow by integrating intelligent cloud solutions. We help you leverage the technologies that make your people more productive, your infrastructure more intelligent, and your business more profitable.
LATEST THINKING
INDIA
Chennai One IT SEZ,
Module No:5-C, Phase ll, 2nd Floor, North Block, Pallavaram-Thoraipakkam 200 ft road, Thoraipakkam, Chennai – 600097
© 2023 CloudIQ Technologies. All rights reserved.