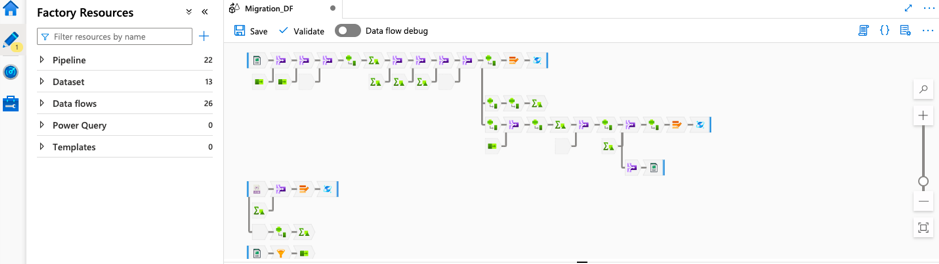
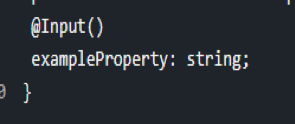
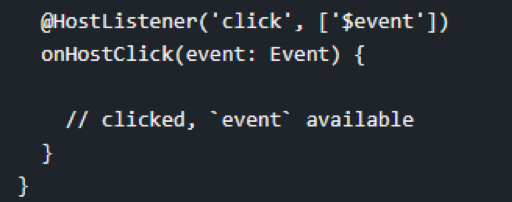
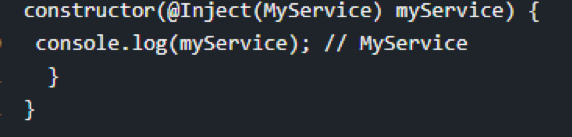
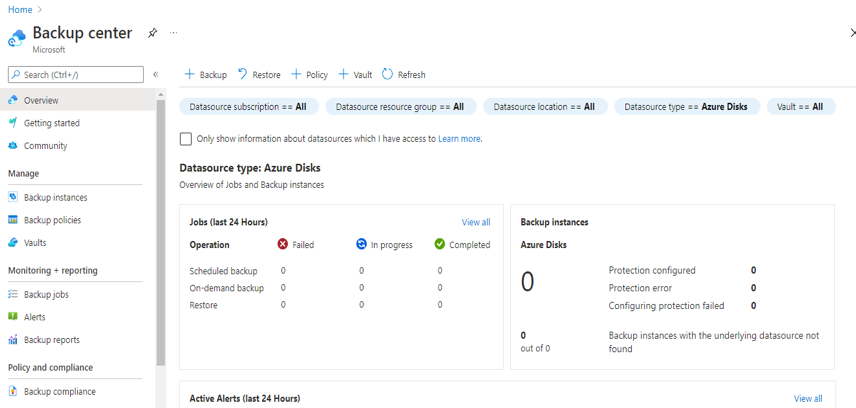
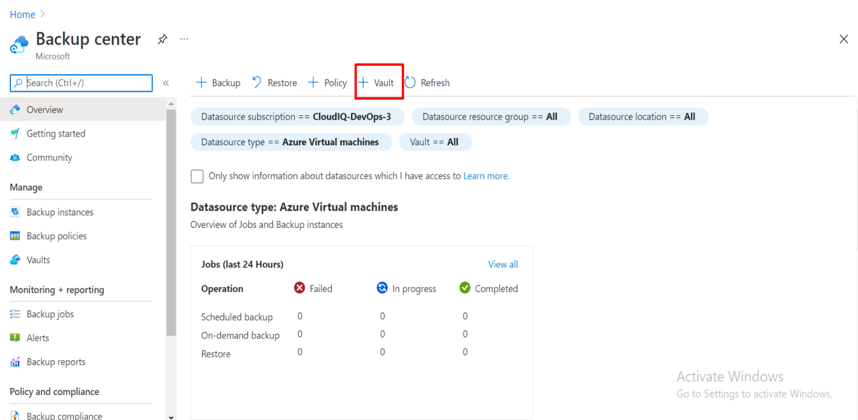
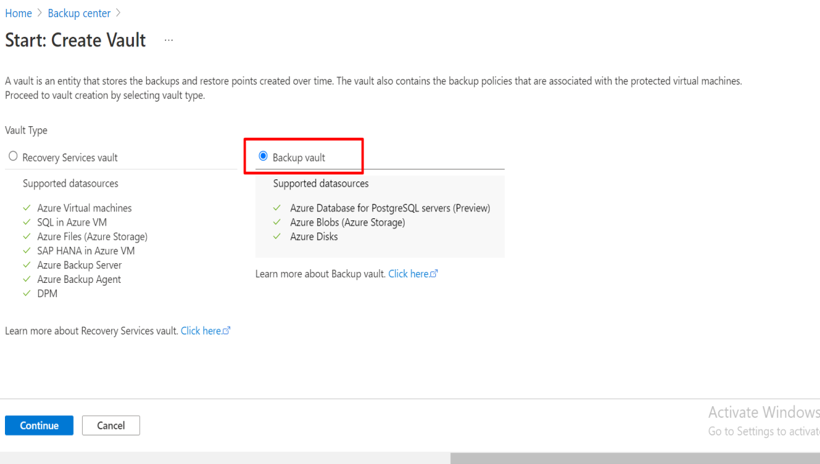
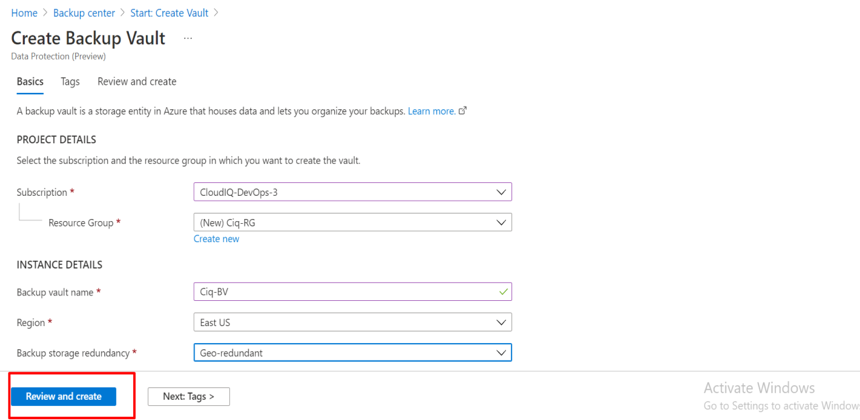
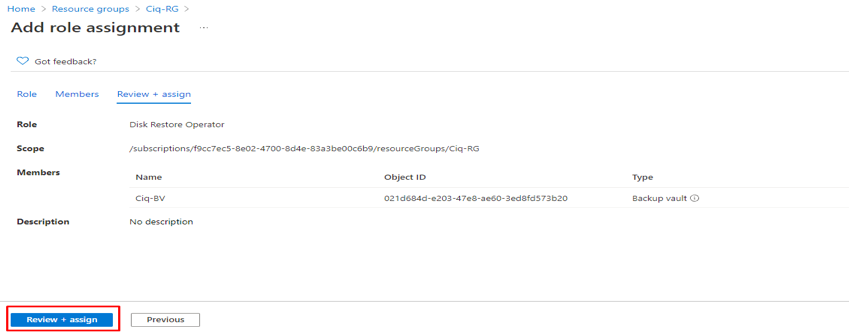
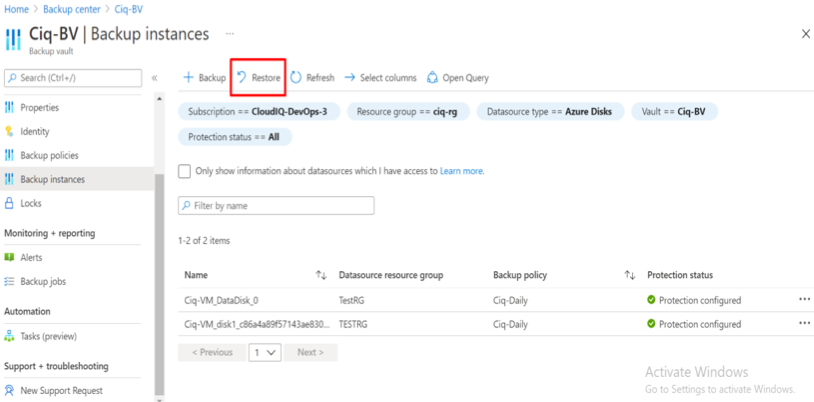
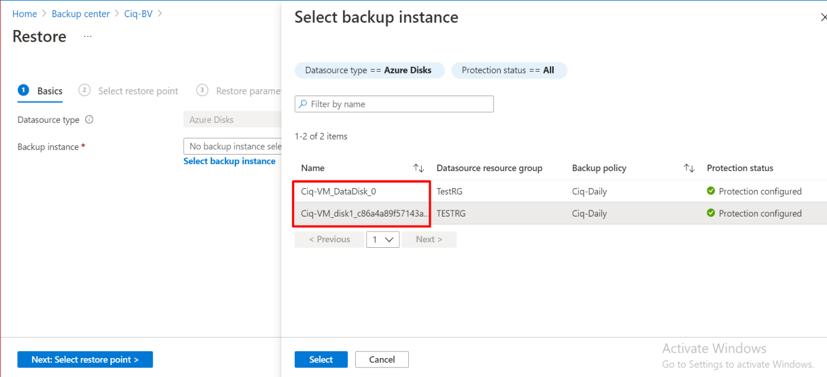
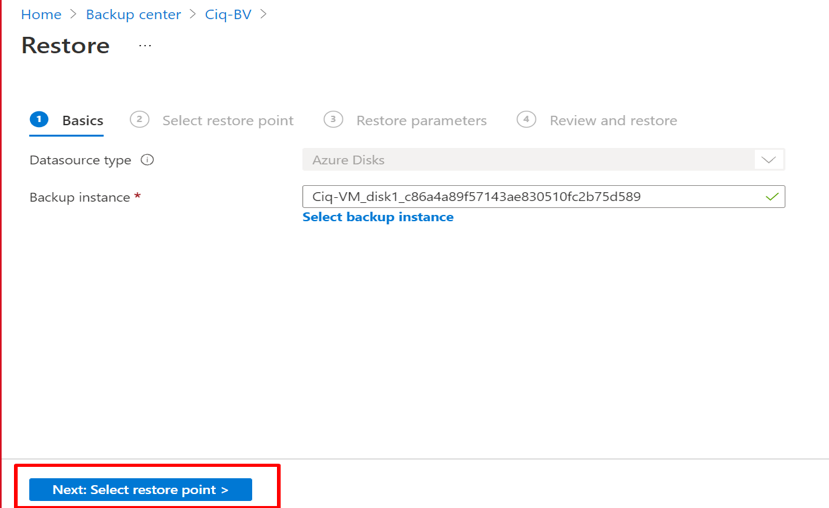
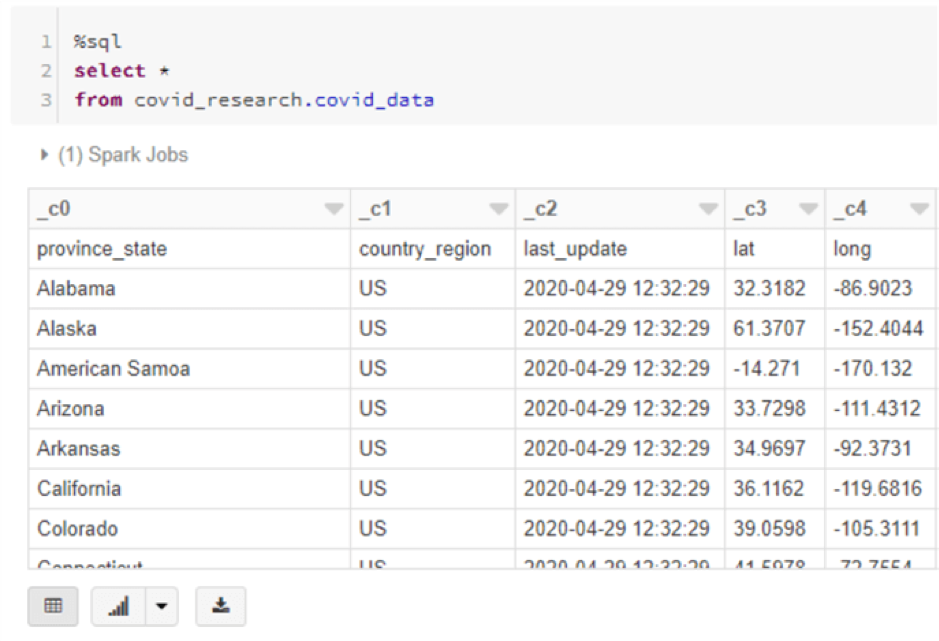
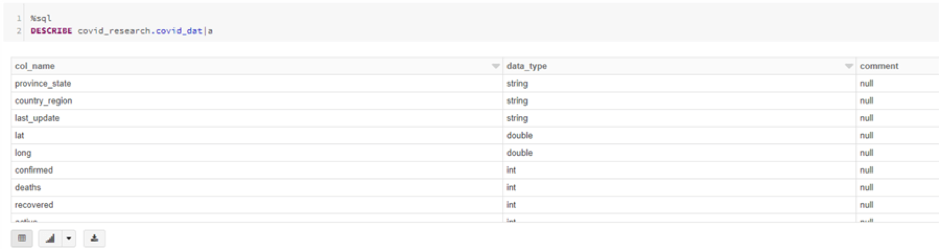
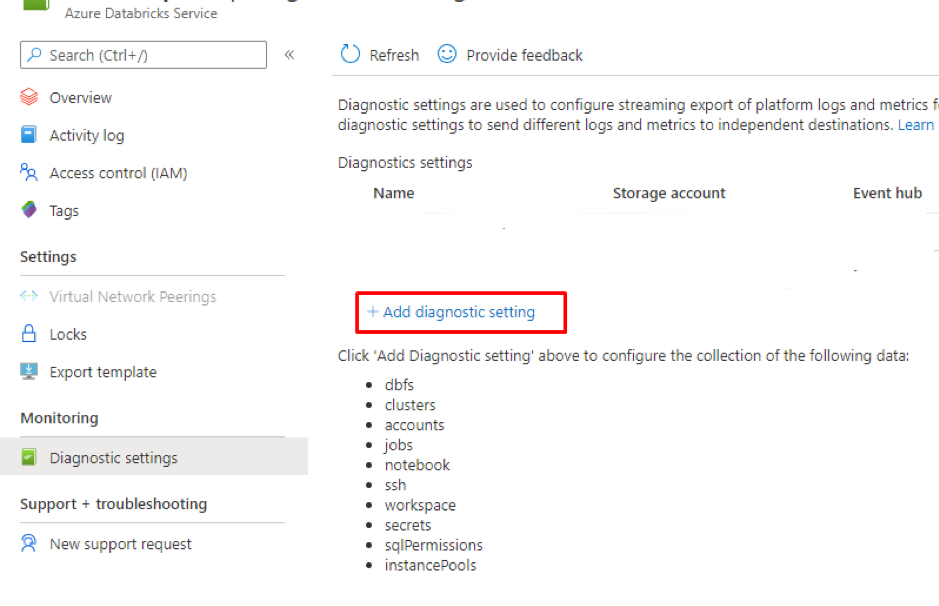
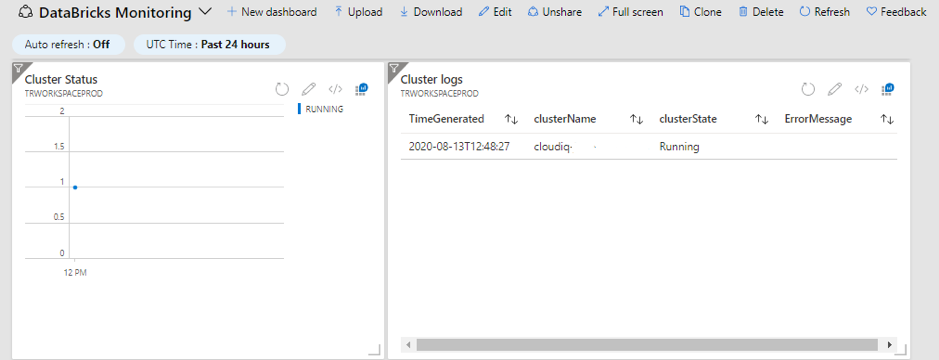
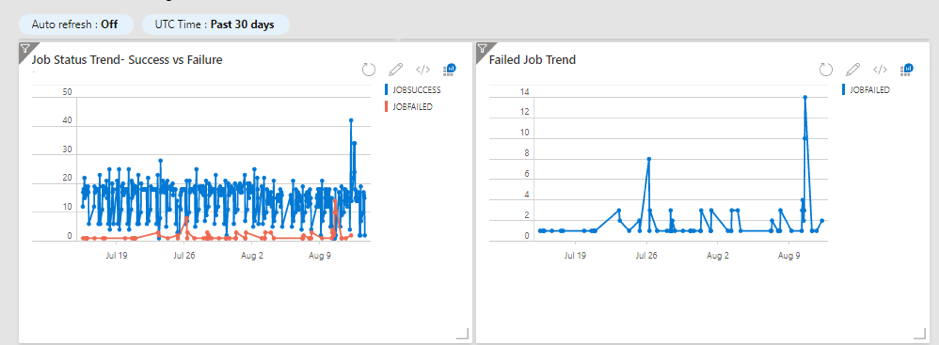
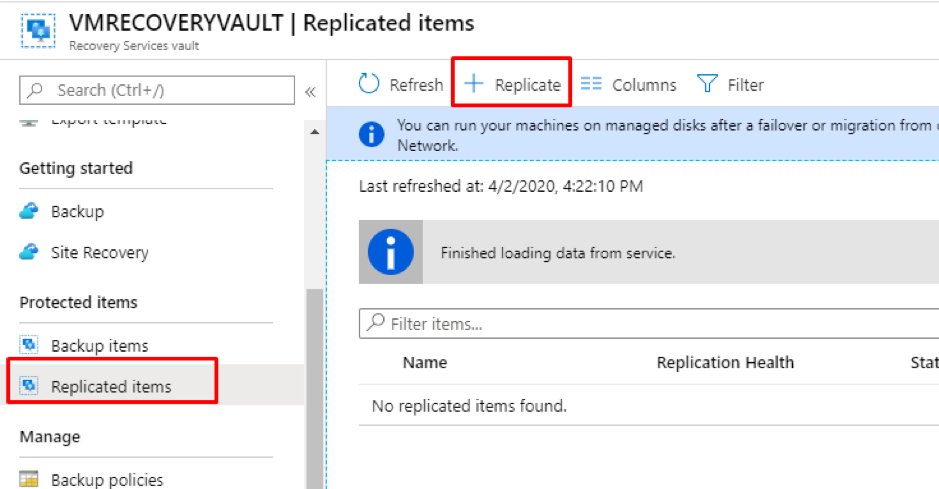
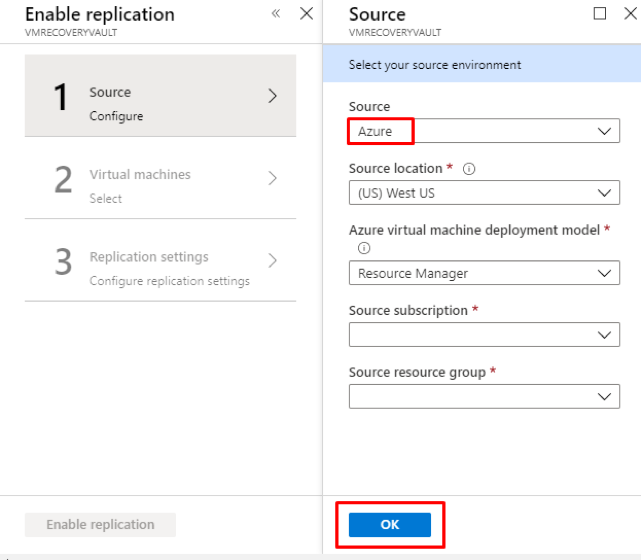
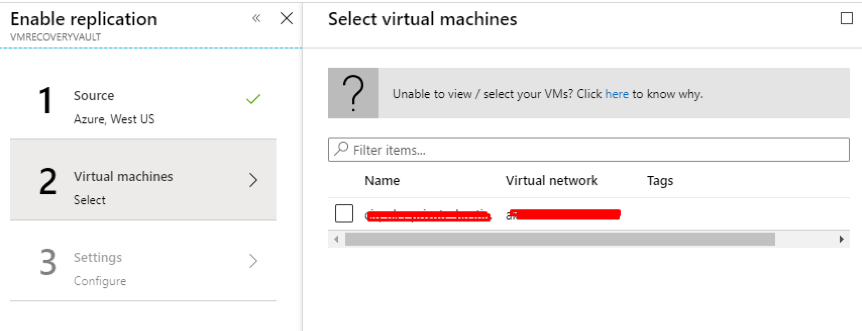
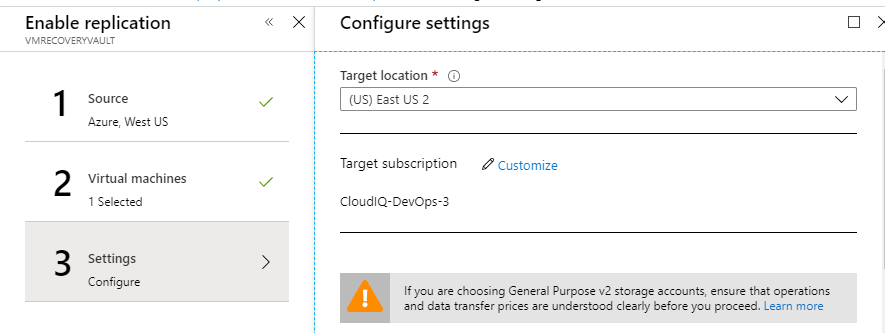
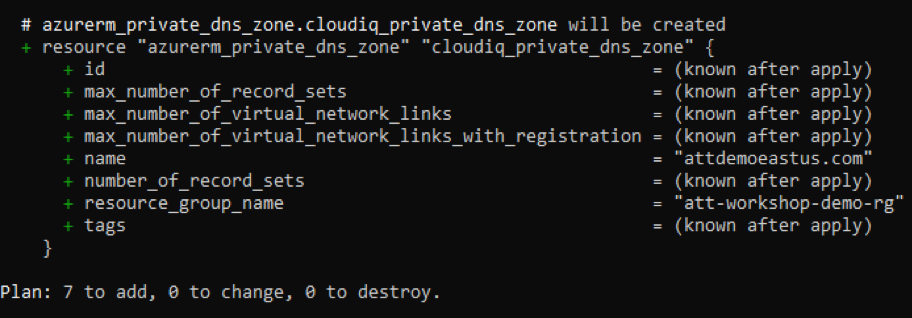
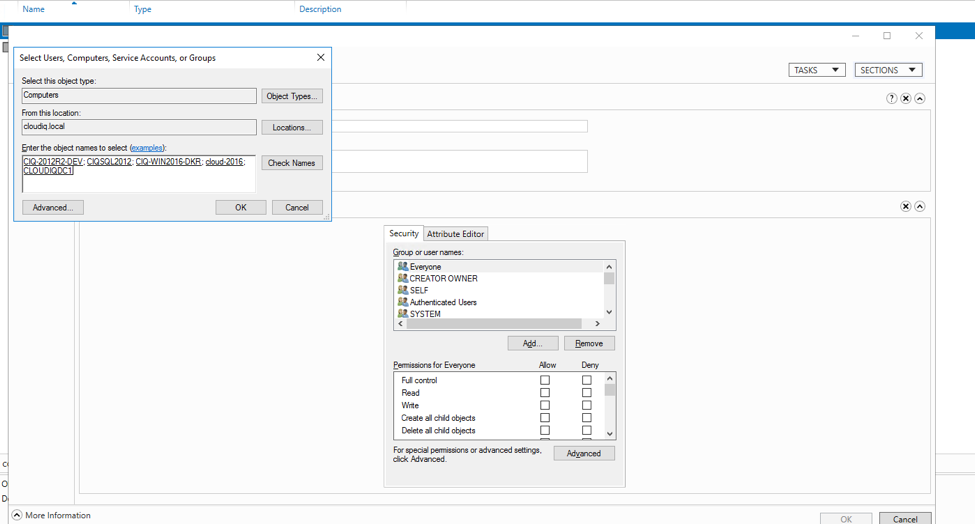
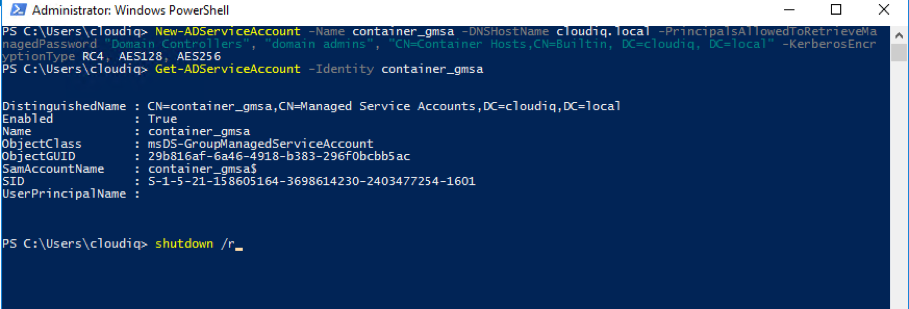
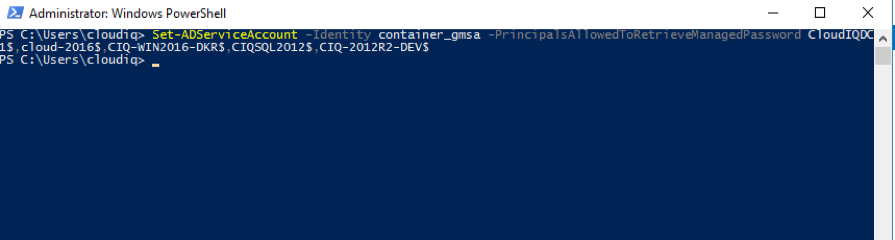
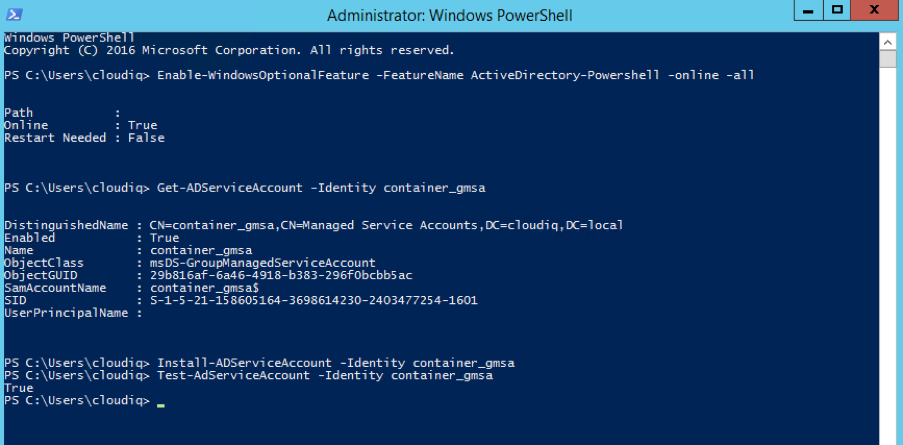
Introduction
In the dynamic world of business, companies are always looking for innovative solutions to enhance competitiveness, drive down costs, and augment profits while embracing sustainability. Enter Artificial Intelligence (AI), a transformative tool that goes beyond mere automation, particularly with the advent of generative AI. This blog aims to explore the deeper layers of how companies can not only leverage AI to cut costs and boost profits but also contribute to building a sustainable future.

1. Automation
At its core, AI’s role in automation extends far beyond streamlining routine processes. Integrating AI into automation processes enables a more nuanced understanding of data, allowing for predictive analysis and proactive decision-making. This, in turn, minimizes downtimes and optimizes resource allocation. Moreover, AI-driven automation facilitates the identification of inefficiencies and bottlenecks that may go unnoticed in traditional systems, enabling companies to fine-tune their processes for maximum efficiency. In terms of cost reduction, AI excels in repetitive and rule-based tasks, reducing the need for manual labor and minimizing errors. Beyond the financial benefits, incorporating AI into automation aligns with sustainability goals by optimizing energy consumption, waste reduction, and overall resource management.
2. Predictive Analytics
AI’s real-time data processing capabilities empower companies with predictive analytics, offering a glimpse into the future of their operations. By analyzing historical data, AI forecasts market trends, customer behaviors, and potential risks. Consider a retail giant utilizing AI algorithms to predict customer preferences. This not only optimizes inventory management but also contributes to waste reduction and sustainability efforts.
By predicting future market trends, customer behavior, and operational needs, businesses can optimize their resource allocation, streamline operations, and minimize waste. This not only trims costs but also enhances profitability by aligning products and services with market demands. Moreover, predictive analytics enables companies to anticipate equipment failures, preventing costly downtime and contributing to a more sustainable operation. Harnessing the power of AI in predictive analytics is not just about crunching numbers; it’s about gaining insights that empower strategic decision-making, fostering a resilient and forward-thinking business model.

3. Personalization at Scale
Generative AI enables hyper-personalization by analyzing vast datasets to understand individual preferences, behaviors, and trends. Companies can utilize advanced algorithms to tailor products or services in real-time, offering a personalized experience that resonates with each customer. This not only fosters customer satisfaction but also drives increased sales and brand loyalty. On the cost front, AI streamlines operations through predictive analytics, optimizing supply chain management, and automating routine tasks. This not only reduces operational expenses but also enhances efficiency. In terms of sustainability, AI aids in resource optimization, minimizing waste and energy consumption. By understanding customer preferences at an intricate level, companies can produce and deliver exactly what is needed, mitigating excess production and waste.
4. Supply Chain Optimization
AI’s pivotal role in optimizing supply chains is revolutionizing sustainability efforts. Generative AI aids in demand forecasting, route optimization, and inventory management, minimizing waste and reducing the carbon footprint. Retail giants like Walmart have successfully implemented AI-powered supply chain solutions, resulting in substantial cost savings and environmental impact reduction.
AI can optimize various facets of the supply chain, from demand forecasting to inventory management. By analyzing historical data and real-time information, AI algorithms can make accurate predictions, preventing overstock or stockouts, thereby minimizing waste and maximizing efficiency. Additionally, AI-driven automation in logistics can streamline operations, cutting down on manual errors and reducing labor costs. Route optimization algorithms can optimize transportation, not only saving fuel and time but also curbing the carbon footprint. Predictive maintenance powered by AI ensures that equipment is serviced proactively, preventing costly breakdowns. Overall, the integration of AI into supply chain processes empowers companies to make data-driven decisions, fostering agility and resilience, ultimately translating into reduced costs, increased profits, and a more sustainable business model.

5. Predictive Maintenance
Generative AI’s impact extends to equipment maintenance, transforming the game by predicting machinery failures. Analyzing data from sensors and historical performance, AI algorithms forecast potential breakdowns, enabling proactive maintenance scheduling. This not only minimizes downtime but also significantly reduces overall maintenance costs, enhancing operational efficiency.
Picture this: instead of waiting for equipment to break down and incurring hefty repair costs, AI algorithms analyze historical data, sensor inputs, and various parameters to predict when machinery is likely to fail. This foresight enables businesses to schedule maintenance precisely when needed, minimizing downtime and maximizing productivity. This involves not just reacting to issues but proactively preventing them. By harnessing AI for predictive maintenance, companies can extend the lifespan of equipment, optimize resource allocation, and, ultimately, boost their bottom line. Moreover, reducing unplanned downtime inherently aligns with sustainability goals, as it cuts down on unnecessary resource consumption and waste associated with emergency repairs.
6. Fraud Detection
The ability of AI to detect patterns and anomalies proves invaluable in combatting fraud. Financial institutions, for instance, deploy generative AI to analyze transaction patterns in real-time, identifying potentially fraudulent activities. This not only safeguards profits but also bolsters the company’s reputation by ensuring a secure environment for customers.
AI systems can analyze vast datasets with unprecedented speed and accuracy, identifying intricate patterns and anomalies that might escape human detection. By deploying advanced machine learning algorithms, companies can create dynamic models that adapt to emerging fraud trends, ensuring a proactive approach rather than a reactive one. This not only minimizes financial losses but also reduces the need for resource-intensive manual reviews. Additionally, AI-driven fraud detection enhances customer trust by swiftly addressing security concerns. By curbing fraud, companies not only protect their bottom line but also contribute to sustainability by fostering a more secure and resilient business environment. It’s a win-win scenario where technology not only safeguards financial interests but aligns with the broader ethos of responsible and enduring business practices.
Conclusion
In conclusion, the integration of AI, especially generative AI, into business operations unveils many opportunities for companies seeking to reduce costs, increase profits, and champion sustainability. From the foundational efficiency of automation to the predictive prowess of analytics, and the personalized touch of generative AI, businesses can strategically utilize these tools for transformative outcomes. Supply chain optimization, predictive maintenance, and content creation further amplify the impact, showcasing the diverse applications of AI.
However, as organizations embark on this AI journey, ethical considerations and environmental consciousness must not be overlooked. Striking a balance between innovation and responsibility is paramount for sustained success. The future belongs to those companies that not only leverage AI for operational excellence but also actively contribute to creating a sustainable and equitable business landscape.