Analytics
Analytics is the discovery, interpretation, and communication of meaningful patterns in data; and the process of applying those patterns towards effective decision making. In other words, analytics can be understood as the connective tissue between data and effective decision making, within an organization. Organizations may apply analytics to business data to describe, predict, and improve business performance.
Big data analytics is the complex process of examining large and varied data sets — or big data — to uncover information including hidden patterns, unknown correlations, market trends and customer preferences that can help organizations make informed business decisions.
Glue, Athena and QuickSight are 3 services under the Analytics Group of services offered by AWS. Glue is used for ETL, Athena for interactive queries and Quicksight for Business Intelligence (BI).
Glue
AWS Glue is a fully managed extract, transform, and load (ETL) service that makes it easy for customers to prepare and load their data for analytics. We can create and run an ETL job with a few clicks in the AWS Management Console. We simply point AWS Glue to our data stored on AWS, and AWS Glue discovers our data and stores the associated metadata (e.g. table definition and schema) in the AWS Glue Data Catalog. Once cataloged, our data is immediately searchable, queryable, and available for ETL.
In this blog we will look at 2 components of Glue – Crawlers and Jobs
Glue Crawlers
Glue crawlers can scan data in all kinds of repositories, classify it, extract schema information from it, and store the metadata automatically in the AWS Glue Data Catalog. From there it can be used to guide ETL operations.
Suppose we have a file named people.json in S3 with the below contents:
{"name":"Ricky","age":22}
{"name":"Jeff","age":36}
{"name":"Geddy","age":62}
Below are the steps to crawl this data and create a table in AWS Glue to store this data:
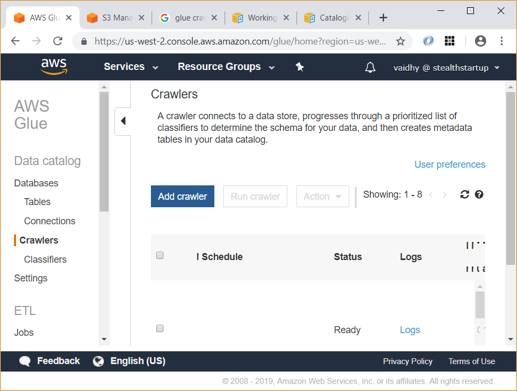
- On the AWS Glue Console, click “Crawlers” and then “Add Crawler”

- Give a name for your crawler and click next
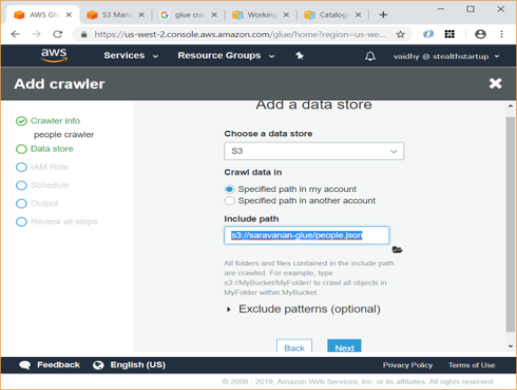
- Select S3 as data source and under “Include path” give the location of json file on S3.
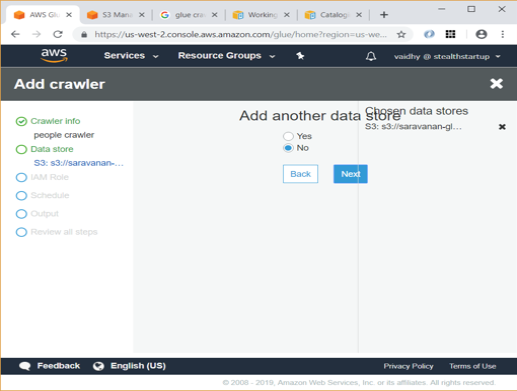
- Since we are going to crawl data from only 1 dataset, select No in next screen and click Next
- In next screen select an IAM role which has access to the S3 data store
- Select Frequency as “Run on demand” in next screen.
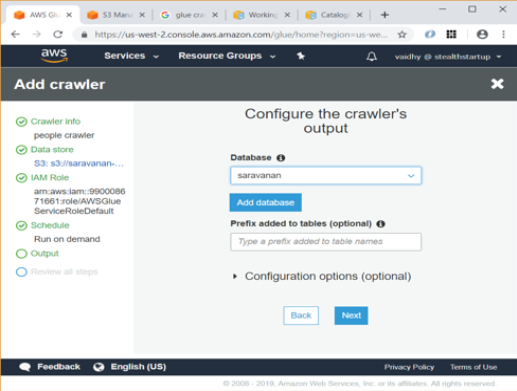
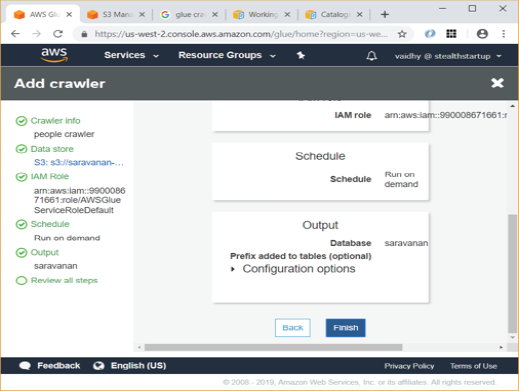
- Select a Database to store the crawler’s output. I chose a database named “saravanan” in the screen below. If no database exists, Add a database using the link given
- Review all details in next step and click Finish
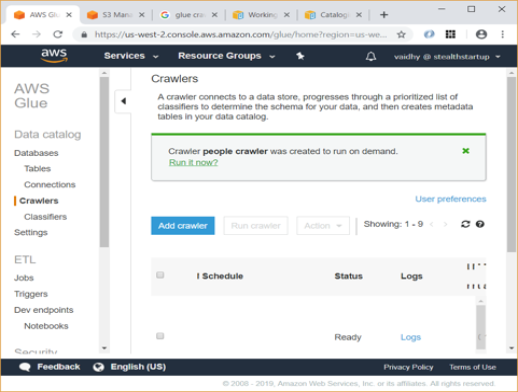
- On next screen, click on “Run it now” to run the crawler
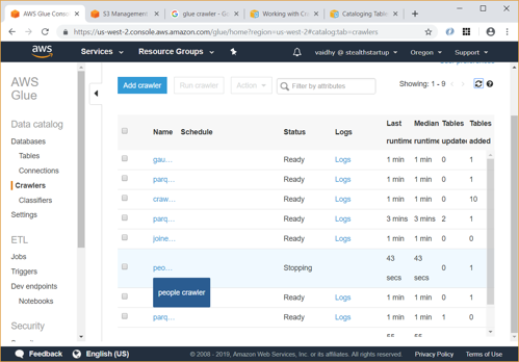
- The crawler runs for around a minute and finally you will be able to see status as Stopping / Ready with Tables added count as 1.
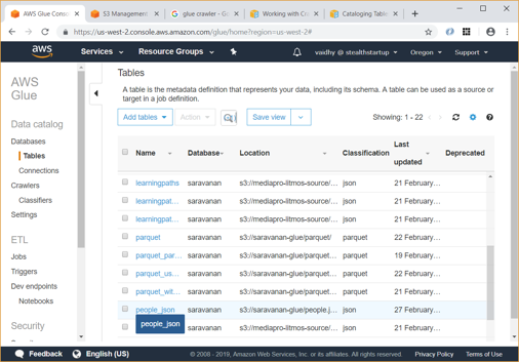
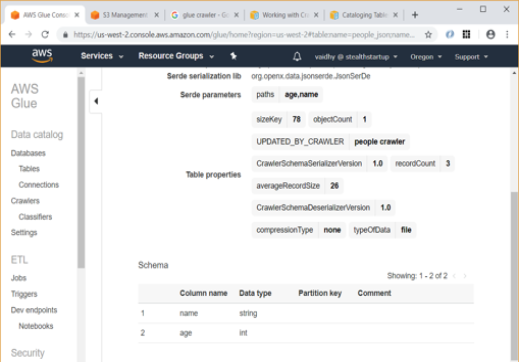
- Now you can go to Tables link and see that a table named “people_json” has been created under “Saravanan” database.
- Using the “View details” Action, and then scrolling down, you can see the schema for the table which Glue has automatically inferred and generated.
Glue jobs
The AWS Glue Jobs system provides managed infrastructure to orchestrate our ETL workflow. We can create jobs in AWS Glue that automate the scripts we use to extract, transform, and transfer data to different locations. Jobs can be scheduled and chained, or they can be triggered by events such as the arrival of new data.
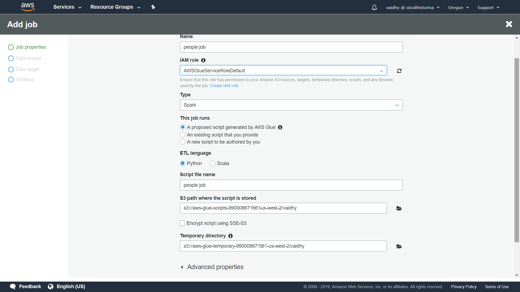
To add a new job using the console
- Open the AWS Glue console, and choose the Jobs tab.
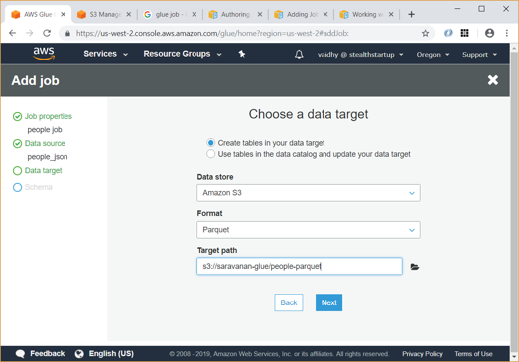
- Choose Add job and follow the instructions in the Add job wizard. Below screens copy data from the table we created earlier to a parquet file named people-parquet in same S3 bucket.
After the above job runs and completes, you will be able to verify in S3 that the output Parquet has been created.
DynamicFrame
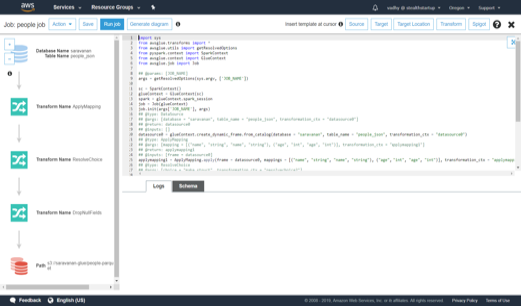
Glue Jobs use a data structure named DynamicFrame. A DynamicFrame is similar to a Spark DataFrame, except that each record is self-describing, so no schema is required initially. Instead, AWS Glue computes a schema on-the-fly when required, and explicitly encodes schema inconsistencies using a choice (or union) type.
Instead of just using the python job which Glue generates, we can code our own jobs using DynamicFrames and have
import sys
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from awsglue.context import GlueContext
glueContext = GlueContext(SparkContext.getOrCreate())
users = glueContext.create_dynamic_frame.from_catalog(
database="saravanan",
table_name="users")
users_courses = glueContext.create_dynamic_frame.from_catalog(
database="saravanan",
table_name="users_courses")
users = users.select_fields(['AccountName','Id','UserName','FullName','Active'])
.rename_field('Active','UserActive')
users_courses = users_courses.select_fields(['UserId', 'Id','Name','Code','Active',
'Complete','PercentageComplete','Overdue']).rename_field('Id','Course_Id')\
.rename_field('Name','CourseName').rename_field('Code','CourseCode').rename_field
('Active','CourseActive').rename_field('Complete','CourseComplete')\
.rename_field('PercentageComplete','CoursePercentageComplete').rename_field
('Overdue','CourseOverDue')
joined_table = Join.apply(users, users_courses, 'Id', 'UserId').drop_fields(['Id'])
joined_table.toDF().write.parquet('s3://saravanan-glue/parquet_partitioned',
partitionBy=['AccountName'])
it run through Glue. The same Glue job on next page selects specific fields from 2 Glue tables, renames some of the fields, joins the tables and writes the joined table to S3 in parquet format.
Athena
Amazon Athena is an interactive query service that makes it easy to analyse data in Amazon S3 using standard SQL. Athena is serverless, so there is no infrastructure to manage, and we pay only for the queries that we run.
Athena is easy to use. We must simply point to our data in Amazon S3, define the schema, and start querying using standard SQL. Most results are delivered within seconds. With Athena, there’s no need for complex ETL jobs to prepare our data for analysis. This makes it easy for anyone with SQL skills to quickly analyse large-scale datasets.
Athena is out-of-the-box integrated with AWS Glue Data Catalog, allowing us to create a unified metadata repository across various services, crawl data sources to discover schemas and populate your Catalog with new and modified table and partition definitions, and maintain schema versioning.
Since Athena uses same Data Catalog as Glue, we will be able to query and view properties of the people_json table which we created earlier using Glue.
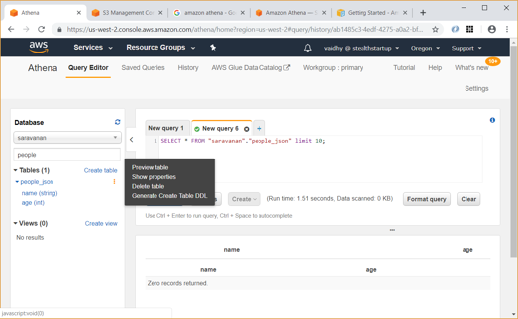
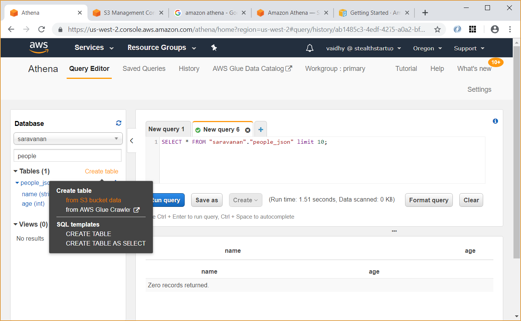
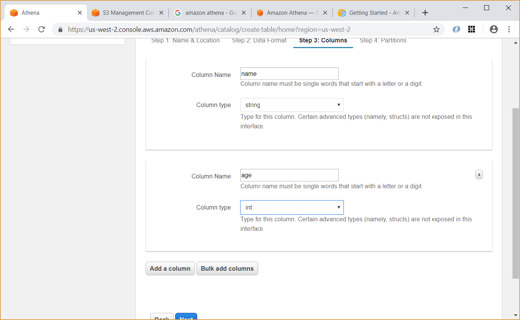
Also, we can create new table using data from S3 bucket data as shown below:
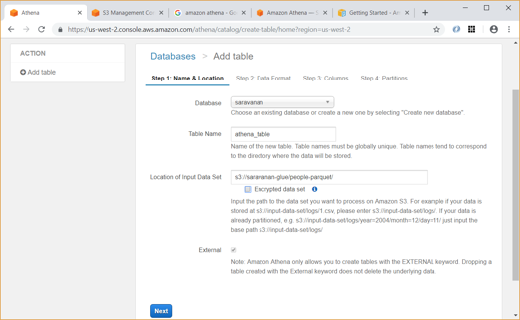
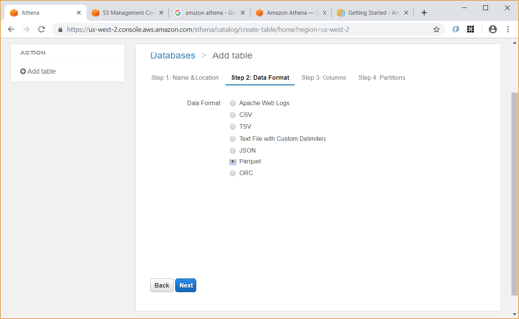
Unlike Glue, we have to explicitly give the data format (CSV, JSON, etc) and specify the column names and types while creating the table in Athena.
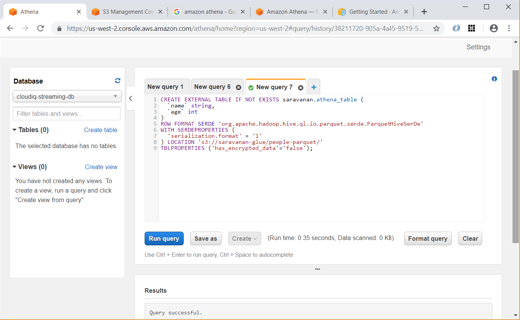
We can also manually create and query the tables using SQL as shown below:
QuickSight
Amazon QuickSight is a fast, cloud-powered business intelligence (BI) service that makes it easy for us to deliver insights to everyone in our organization.
QuickSight lets us create and publish interactive dashboards that can be accessed from browsers or mobile devices. We can embed dashboards into our applications, providing our customers with powerful self-service analytics.
QuickSight easily scales to tens of thousands of users without any software to install, servers to deploy, or infrastructure to manage.
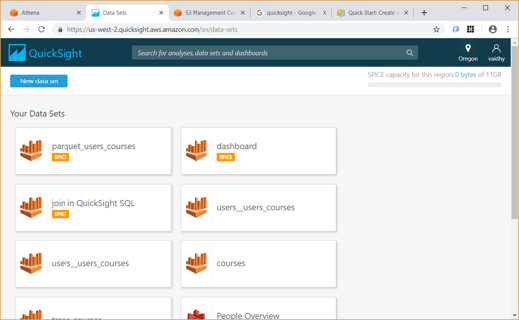
Below are the steps to create a sample Analysis in QuickSight:
- Any Analysis in QuickSight requires data from a Data Set. First click on the “Manage data” link at top right to list the Data Sets we currently have.
- To create a new Data Set, click the “New data set” link
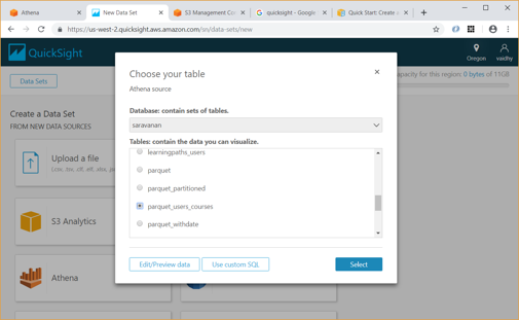
- We can create Data Set from any of the Data sources listed here – uploading a file, S3, Athena table, etc.
- For our example, I am selecting Athena as data source and giving it a name “Athena source”. Then we must map this to a database / table in Athena.
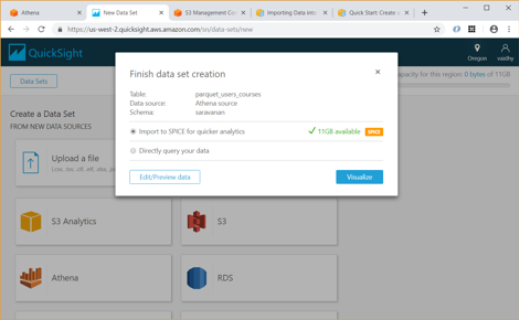
- After we select the Athena table, QuickSight provides us an option to import the data to SPICE. SPICE is Amazon QuickSight’s in-memory optimized calculation engine, designed specifically for fast, adhoc data visualization. SPICE stores our data in a system architected for high availability, where it is saved until we choose to delete it.
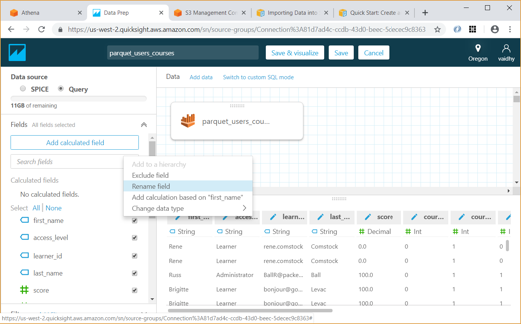
- Using the Edit/Preview Data option above allows us to select the columns to be included in Data set and rename them if required.
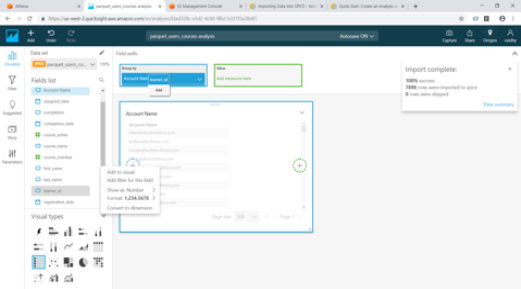
- Once we click the “Save & visualize” link above, QuickSight starts creating an Analysis for us. For our exercise we will select the Table visual type from the list.
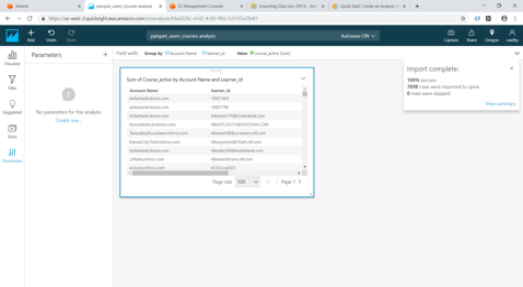
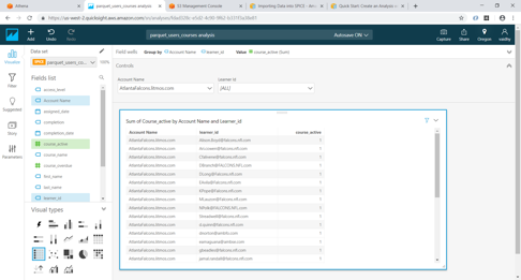
- Add Account Name and User_id by dragging them from “Fields list” to “Group by” and course_active to “Value”
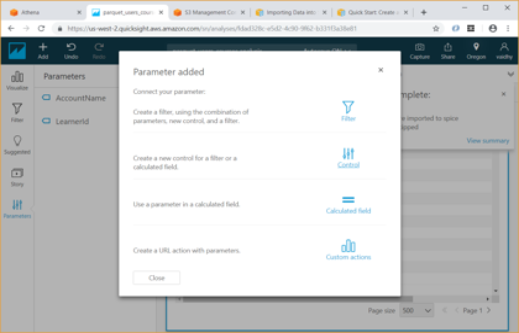
- Now we will add 2 parameters for Account Name and Learner id by clicking on Parameters at bottom left. While creating the parameter use the option “Link to a data set field” for Values and link the parameter to the appropriate column in the Athena table
- Once the parameters are added, create controls for the parameters. If we are adding 2 parameters with controls, we have option of showing only relevant values for second parameter based on the values selected for first parameter. For this select the “Show relevant values only” checkbox.
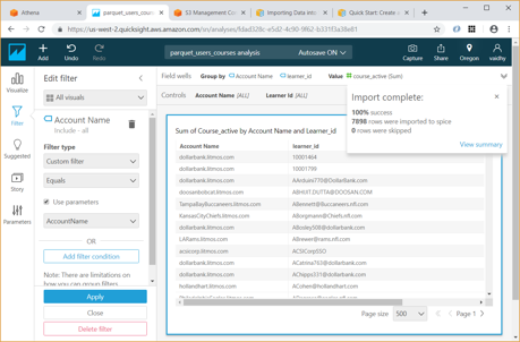
- Next add 2 Custom filters for Account Name and Learner id. These filters should me mapped to the parameters we had created earlier. For this choose the Filter type as “Custom filter” and select the “Use parameters” checkbox.
- Now using the Visualize option, we can verify if our Controls are working correctly
- To share the Dashboard with others, use the share option on top towards the right and use publish dashboard. We can search for users of the AWS account by email and publish to selective users.
Share this:
CloudIQ is a leading Cloud Consulting and Solutions firm that helps businesses solve today’s problems and plan the enterprise of tomorrow by integrating intelligent cloud solutions. We help you leverage the technologies that make your people more productive, your infrastructure more intelligent, and your business more profitable.
LATEST THINKING
INDIA
Chennai One IT SEZ,
Module No:5-C, Phase ll, 2nd Floor, North Block, Pallavaram-Thoraipakkam 200 ft road, Thoraipakkam, Chennai – 600097
© 2023 CloudIQ Technologies. All rights reserved.