Apache Spark
Apache Spark is an open-source parallel processing framework for running large-scale data analytics applications across clustered computers. It can handle both batch and real-time analytics and data processing workloads.
Spark provides distributed task transmission, scheduling, and I/O functionality. It provides programmers with a potentially faster and more flexible alternative to MapReduce, the software framework to which early versions of Hadoop were tied.
How Apache Spark works
Apache Spark can process data from a variety of data repositories, including the Hadoop Distributed File System (HDFS), NoSQL databases and relational data stores.
The Spark Core engine uses the resilient distributed data set, or RDD, as its primary data type. The RDD is designed in such a way to hide much of the computational complexity from users. It aggregates data and partitions it across a server cluster, where it can then be computed and either moved to a different data store or run through an analytic model. The user doesn’t have to define where specific files are sent or what computational resources are used to store or retrieve files.
Given below is a sample Spark program written in Python to count the number of records with each rating in the input file given in next page:
from pyspark import SparkConf, SparkContext
import collections
conf = SparkConf().setMaster("local").setAppName("RatingsHistogram")
sc = SparkContext(conf = conf)
lines = sc.textFile("file:///SparkCourse/ml-100k/u.data")
ratings = lines.map(lambda x: x.split()[2])
result = ratings.countByValue()
sortedResults = collections.OrderedDict(sorted(result.items()))
for key, value in sortedResults.items():
print("%s %i" % (key, value))
In the above code, sc is the SparkContext associated with input file u.data. ratings is a RDD created by mapping the 3rd column in input file (array occurrence [2] – Ratings). Here map() is a transformation function which produces a new RDD.
We can have multiple transformations in a single spark program each producing a new RDD from an existing RDD or an input file. countByValue() is an Action that is performed.
In Spark, the transformations are not executed until an Action is triggered. This is called Lazy Evaluation.
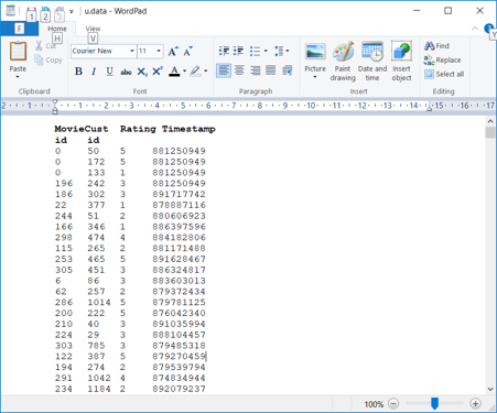
Figure 1
Spark languages
Spark was written in Scala, which is considered the primary language for interacting with the Spark Core engine. Out of the box, Spark also comes with API connectors for using Java, R, and Python.
Spark libraries
- The Spark Core engine functions partly as an application programming interface (API) layer and underpins a set of related tools for managing and analyzing data.
- Spark SQL — One of the most commonly used libraries, Spark SQL enables users to query data stored in disparate applications using the common SQL language.
- Spark Streaming — This library allows users to build applications that analyze and present data in real time.
- MLlib — A library of machine learning code that enables users to apply advanced statistical operations to data in their Spark cluster and to build applications around these analyses.
- GraphX — A built-in library of algorithms for graph-parallel computation.
RDDs, DataFrames, and Datasets
An RDD is an immutable distributed collection of elements of data, partitioned across nodes in a cluster that can be operated in parallel with a low-level API that offers transformations and actions.
Like an RDD, a DataFrame is an immutable distributed collection of data. However, unlike an RDD, data is organized into named columns, like a table in a relational database.
Datasets in Apache Spark are an extension of DataFrame API which provides type-safe, object-oriented programming interface.
Executing SQL-style functions on a Dataframe
Given below is a map-reduce program to get the list of popular movies (which has been rated by many customers using the same input data as Figure 1 above).
from pyspark import SparkConf, SparkContext
conf = SparkConf().setMaster("local").setAppName("PopularMovies")
sc = SparkContext(conf = conf)
lines = sc.textFile("file:///SparkCourse/ml-100k/u.data")
movies = lines.map(lambda x: (int(x.split()[1]), 1))
movieCounts = movies.reduceByKey(lambda x, y: x + y)
flipped = movieCounts.map( lambda xy: (xy[1],xy[0]) )
sortedMovies = flipped.sortByKey()
results = sortedMovies.collect()
for result in results:
print(result)
The same program, when written using DataFrames, will look like this
from pyspark.sql import SparkSession
from pyspark.sql import Row
from pyspark.sql import functions
def loadMovieNames():
movieNames = {}
with open("ml-100k/u.ITEM") as f:
for line in f:
fields = line.split('|')
movieNames[int(fields[0])] = fields[1]
return movieNames
# Create a SparkSession (the config bit is only for Windows!)
spark = SparkSession.builder.config("spark.sql.warehouse.dir",
"file:///C:/temp").appName("PopularMovies").getOrCreate()
# Load up our movie ID -> name dictionary
nameDict = loadMovieNames()
# Get the raw data
lines = spark.sparkContext.textFile("file:///SparkCourse/ml-100k/u.data")
# Convert it to a RDD of Row objects
movies = lines.map(lambda x: Row(movieID =int(x.split()[1])))
# Convert that to a DataFrame
movieDataset = spark.createDataFrame(movies)
# Some SQL-Style magic to sort all movies by popularity in one line!
topMovieIDs = movieDataset.groupBy("movieID").count().orderBy
("count", ascending=False).cache()
# Show the results at this point:
#|movieID|count|
#+-------+-----+
#| 50| 584|
#| 258| 509|
#| 100| 508|
topMovieIDs.show()
# Grab the top 10
top10 = topMovieIDs.take(10)
# Print the results
print("\n")
for result in top10:
# Each row has movieID, count as above.
print("%s: %d" % (nameDict[result[0]], result[1]))
# Stop the session
spark.stop()
As you can see DataFrames gives us the flexibility to use SQL style functions to get the required results. Because DataFrames APIs are built on top of the Spark SQL engine, it uses Catalyst to generate an optimized logical and physical query plan.
Job Scheduling
Spark has several facilities for scheduling resources between computations.
- Each Spark application (instance of SparkContext) runs an independent set of executor processes. The cluster managers that Spark runs on provide facilities for scheduling across applications.
- Within each Spark application, multiple “jobs” (Spark actions) may be running concurrently if they were submitted by different threads. This is common if the application is serving requests over the network. Spark includes a fair scheduler to schedule resources within each SparkContext.
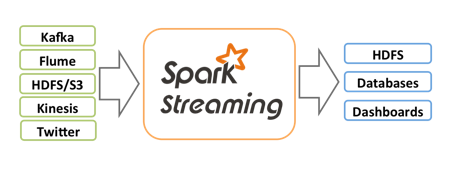
Spark Streaming
Spark Streaming is an extension of the core Spark API that enables scalable, high-throughput, fault-tolerant stream processing of live data streams. Data can be ingested from many sources like Kafka, Flume, Kinesis, or TCP sockets, and can be processed using complex algorithms expressed with high-level functions like map, reduce, join and window. Finally, processed data can be pushed out to filesystems, databases, and live dashboards.
The Python program shown below counts the number of words in text data received from a data server listening on a TCP socket.
Sample input entered for this program at a terminal through NetCat and the output of the program is given below.
# TERMINAL 1:
# Running Netcat
$ nc -lk 9999
hello world
...
# TERMINAL 2: RUNNING network_wordcount.py
$ ./bin/spark-submit examples/src/main/python/streaming/network_wordcount.py
localhost 9999
...
-------------------------------------------
Time: 2014-10-14 15:25:21
-------------------------------------------
(hello,1)
(world,1)
...
Conclusion
Launched for the first time in May 2014, Apache Spark has become the go-to program for companies that work with large-scale Big Data applications. The speed and agility of Spark have made it incredibly useful across a wide range of industries.
From FMCG giants to BFSI companies to digital advertising firms – Apache Spark has proved to be indispensable when it comes to aggregating data, gleaning insights and forecasting industry trends.
Share this:
CloudIQ is a leading Cloud Consulting and Solutions firm that helps businesses solve today’s problems and plan the enterprise of tomorrow by integrating intelligent cloud solutions. We help you leverage the technologies that make your people more productive, your infrastructure more intelligent, and your business more profitable.
LATEST THINKING
INDIA
Chennai One IT SEZ,
Module No:5-C, Phase ll, 2nd Floor, North Block, Pallavaram-Thoraipakkam 200 ft road, Thoraipakkam, Chennai – 600097
© 2023 CloudIQ Technologies. All rights reserved.